布局转换算法#
接着上节中我们对卷积神经网络的特征图存储方式的讨论。 NHWC 的数据排布方式更适合多核 CPU 运算, NCHW 的数据排布方式更适合 GPU 并行运算。那么接下来让我们了解一下在华为昇腾的 NPU 中,这种特征图的存储方式。
截止到 2024 年,华为昇腾在私有格式的数据处理和特殊的数据形态越来越少,主要是得益于 AI 编译器和软件的迭代升级,更加合理地兼容业界主流的算子和数据排布格式。
昇腾数据排布#
昇腾数据排布格式#
我们在上半篇曾提到过,数据排布格式的转换主要是将内部数据布局转换为硬件设备友好的形式,实际在华为昇腾的 AI 处理器中,为了提高通用矩阵乘法运算和访存的效率,一般既不选择 NHWC,也不选择 NCHW 来对多维数据进行存储。
这里我们将华为昇腾的数据排布作为一个案例,这种多维数据统一采用 NC1HWC0 的五维数据格式进行存储,具体的含义是将数据从 C 维度分割成 C1 份 C0。
如下图中所示,下图中将 N 这个维度进行了省略,原先的红色长方体展现的是 CHW 三个维度,将它在 C 维度分割成 C1 个长方体,每个长方体的三个维度为 C0HW,而后将这 C1 份长方体在内存中连续排列,此处的 C1=C/C0,如果不能除尽则向上取整,对应着上半篇中的内存对齐,也就是通道现在变成了 C0 个,其中 C0 对于 FP16 类型为 16,对于 INT8 类型则为 32,这部分数据需要连续存储。
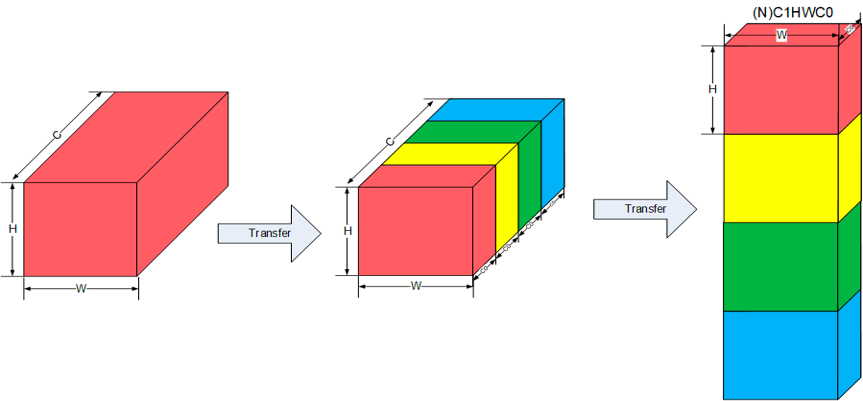
这样子的数据排布我们从硬件的角度来进行分析,华为的达芬奇架构在 AI Core 中特意优化了矩阵乘法单元,矩阵计算单元可以快速完成两个 16x16 矩阵的相乘运算,等同于可以在极短时间内进行 \(16^3=4096\) 个乘加运算,并且可以实现 FP16 的运算精度,也就是说其可以针对 16 个 FP16 类型的数据进行快速的计算。这也就是我们对 C0 在 FP16 类型取 16,INT8 类型取 32 的部分原因。
下面我们来介绍一下如何转换出 NC1HWC0 数据格式,即将 NHWC 转换为 NC1HWC0 数据格式。具体操作:
1.将 NHWC 数据在 C 维度进行分割,变成 C1 份 NHWC0。
2.将 C1 份 NHWC0 在内存中连续排列,由此变成 NC1HWC0。
pytorch 中代码如下所示
Tensor.reshape([N, H, W, C1, C0]).transpose([0, 3, 1, 2, 4])
将 NCHW 转换为 NC1HWC0 数据格式
Tensor.reshape([N, C1, C0, H, W]).transpose([0, 1, 3, 4, 2])
Fractal Z & NZ 格式#
ND 格式 (N-Dimension),是神经网络中最常见且最基本的张量存储格式,代表 N 维度的张量数据。
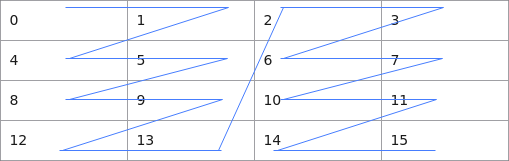
为了在达芬奇架构中更高效的搬运和进行矩阵计算,引入一种特殊的数据分形格式,NZ 格式。 如下图所示,我们以 4*4 的矩阵来进行举例,按照 NZ 格式数据在内存中的排布格式为[0,1,4,5,8,9,12,13,2,3,6,7,10,11,14,15],按照 ND 格式数据在内存中的排布格式为[0, 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]。
如下图所示,NZ 分形操作中,整个矩阵被分为(H1 * W1)个分形,分形之间按照列主序排布,即类比行主序的存储方式,列主序是先存储一列再存储相邻的下一列,这样整体存储形状形如 N 字形;每个分形内部有(H0 * W0)个元素,按照行主序排布,形状如 Z 字形。
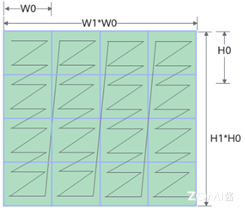
下面我们详细地对 NZ 格式(也被称为 NW1H1H0W0 格式)具体在内存中存储的维度优先顺序进行展开。先对一个分形内部进行行主序存储,再在一个完整矩阵中以分形宽度为划分,进行列主序存储,再依次对相邻的下一个矩阵进行存储。即此方式先按 W0 方向存储,再按 H0 方向存储,接着按照 H1 方向存储,随后按照 W1 方向存储,最后按 N 方向存储,直到所有数据存储完成。
下面我们介绍一下如何将 ND 数据格式转换为 NZ 数据格式:
将 ND 转换为 NZ 数据格式
1 (..., N,H, W )->pad->(..., N, H1*H0, W1*W0)->reshape->(..., N, H1, H0, W1, W0)->transpose->(..., N, W1, H1, H0, W0)
其中 pad 为平铺操作,reshape 将张量进行拆分,形状重塑,transpose 为转置操作。
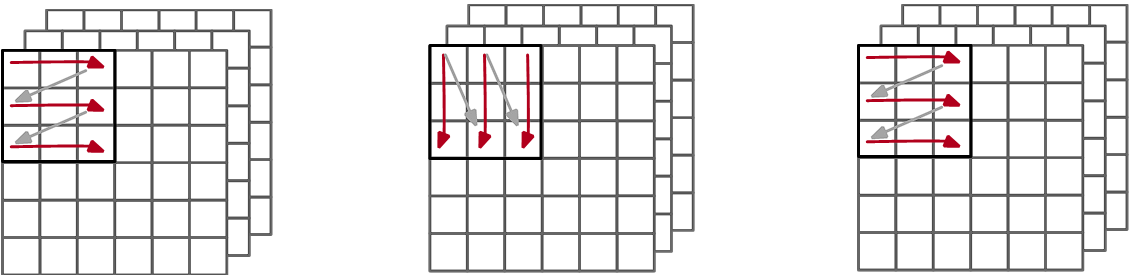
除了 ND 和 NZ 格式,还有其他数据格式,如下图所示,图中最左侧小 z 大 Z,即为 ND 格式示意图,块内按照行排序,块间也按照行排序,常用于特征图的数据存储。
图中中间部分为小 n 大 Z,块内按照列排序,块间按照行排序,常用于权重的数据存储。图中右侧部分为小 z 大 N,即为 NZ 格式示意图,块内按照行排序,块间按照列排序,常用于卷积结果的输出。
AI 编译器布局转换算法#
了解了基础知识与部分硬件中应用后,我们来了解一下在 AI 编译器中如何对数据布局进行转换优化。
首先,我们转换数据布局的目的是将将内部数据布局转化为后端设备(硬件)友好的形式,我们需要做的是尝试找到在计算图中存储张量的最佳数据布局,然后将布局转换节点插入到图中。
但其中有个需要十分注意的地方,布局转换也是需要很大的开销的,一旦涉及布局转换,就会有 I/O 操作,其产生的代价能否比的上数据格式转换后带来的性能优化也是需要我们重点考虑的部分。
具体地来说,比如 NCHW 格式操作在 GPU 上通常运行得更快,所以在 GPU 上转换为 NCHW 格式是较为有效的操作。
一些 AI 编译器依赖于特定于硬件的库来实现更高的性能,而这些库可能需要特定的布局,比如华为昇腾的 AI 编译器就依赖于 CANN 库,其中的特定布局我们在上文中已经提到。
同时也有许多设备需要配备异构计算单元,比如手机,其 SOC 中有丰富的 IP,arm 端侧的 GPU 还有 ISP 以及 DPU 等一系列不同计算单元。不同的单元可能需要不同的数据布局以更好地利用数据,这就需要 AI 编译器提供一种跨各种硬件执行布局转换的方法。
下面我们来看看数据转换具体是如何操作的。如下图所示,这两个都是数据转换的算子,数据转换我们在这里用 CASTDATA 算子来表示,左侧输入的数据格式为 NHWC,输出的数据格式为 NCHW,那么就需要一个数据转换算子节点来将数据格式由 NHWC 转换为 NCHW,右侧则相反过来,此处不再赘述。
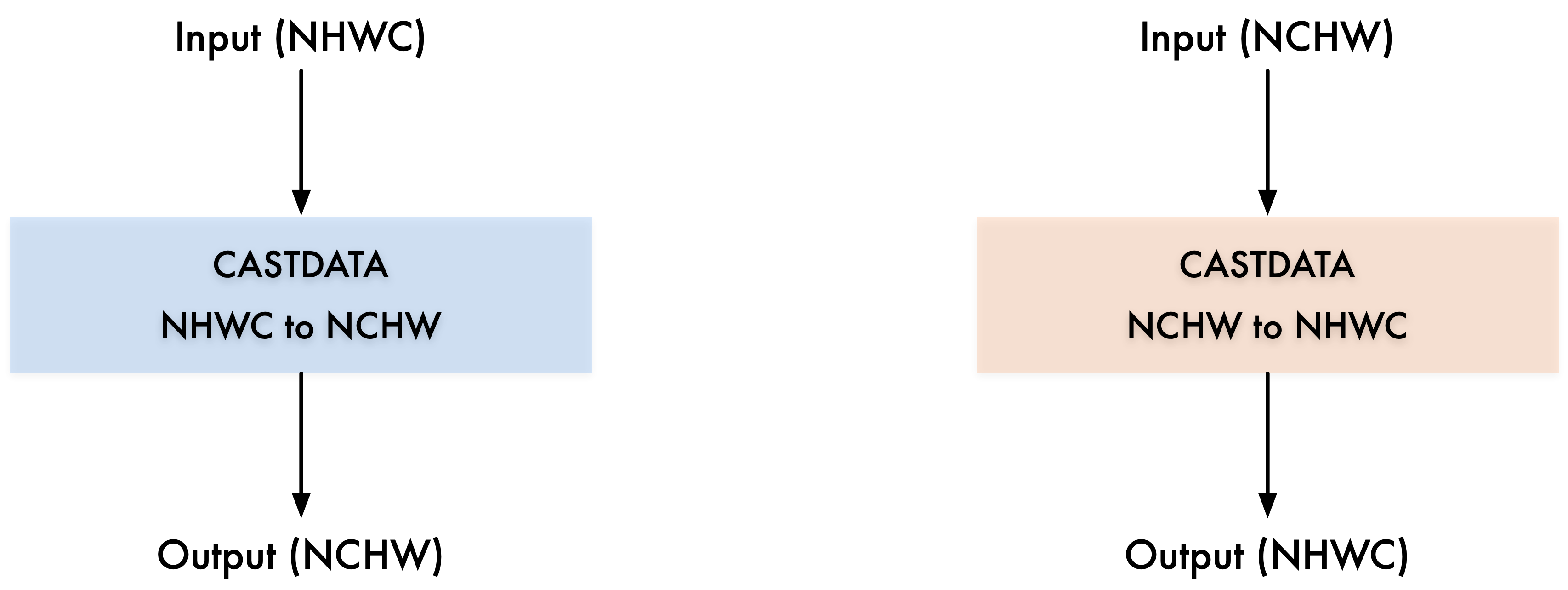
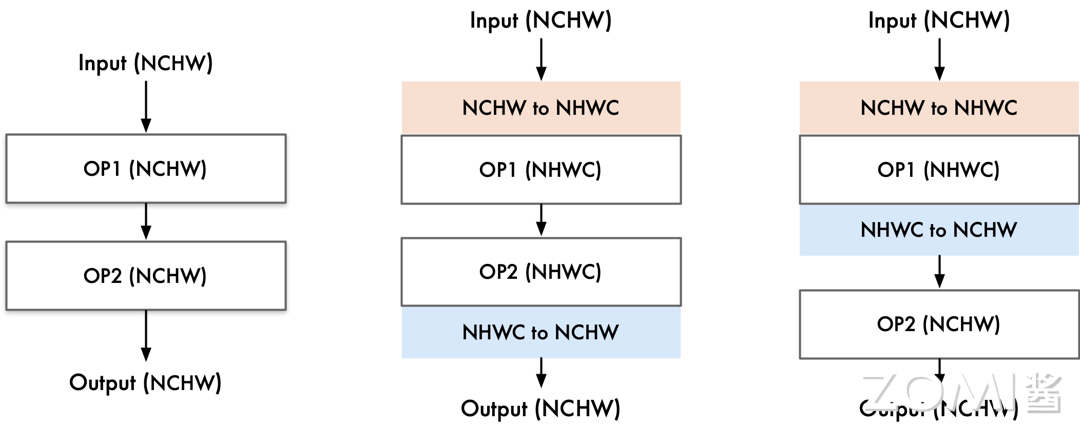
接下来,我们来看略复杂一些的数据转换。如下图所示,首先像最左侧,此处我们两个算子使用的数据格式与输入输出时都相同,为 NCHW,那么此时 AI 编译器中就不需要加入数据转换节点。
中间部分,输入的数据格式为 NCHW,算子一需求的数据格式为 NHWC,需要在两者之间插入一个 CASTDATA NCHW TO NHWC 算子进行数据转换,算子二格式也为 NHWC,数据格式相同,不需要转换,输出的数据格式为 NCHW,那么在算子二到输出间需要插入一个 CASTDATA NHWC TO NCHW 算子进行数据转换。
最右侧的图中,输入的数据格式为 NCHW,算子一需求的数据格式为 NHWC,需要在两者之间插入一个 CASTDATA NCHW TO NHWC 算子进行数据转换,算子二格式为 NCHW,需要在算子一到算子二之间插入一个 CASTDATA NHWC TO NCHW 算子进行数据转换。输出与算子二数据格式相同,不做额外处理。
首先我们来讲解一下训练场景下 AI 编译器的例子,例如 1×1 的卷积常常使用 NHWC 的数据格式,而如果到后面使用的是 3×3 的卷积常常使用 NCHW 的数据格式,AI 编译器此时能够感知上下文,得到这些存储格式的信息,这时候 AI 编译器就会根据具体的数据格式插入需要的转换算子,并且整个过程不会改变原先原计算图的其他内容。
再假设此时我们使用的是三个连续的 1×1 的卷积算子,使用的都是 NHWC 的数据格式,算子之间的数据格式是一样的,那么此时 AI 编译器需要取消掉多余的转换算子。
接着我们来讲解一下推理场景下 AI 编译器与训练场景下有什么不同,其中较大的区别是与会有在权重数据进行布局的转换。假设训练时使用的是 GPU 对神经网络进行训练,但是推理的时候会在更多的场景下进行使用,比如手机上进行推理,手机上较多使用的是 CPU,其进行推理时与在 GPU 上进行训练时的权重数据的布局可能会有所不同,那么此时就需要 AI 推理编译器插入一个权重布局的转换。
小结与思考#
卷积神经网络的特征图在华为昇腾 NPU 中的存储的数据排布格式,为 NC1HWC0 的五维数据格式,是将数据从 C 维度分割成 C1 份 C0,原因是能够更好地贴合华为的达芬奇架构中优化的矩阵乘法单元。
华为昇腾 NPU 中的张量存储的数据排布格式,有 ND,NZ,以及小 n 大 Z 等等数据格式。
AI 编译器中具体对数据布局进行转换优化的方式:插入 CASTDATA 算子进行数据转换,或者消除 CASTDATA 算子,亦或是推理场景下对权重布局的转换,都是为了计算图在对应硬件环境下能够完整执行。