QNNPack 算法#
QNNPACK(Quantized Neural Networks PACKage 是 Marat Dukhan (Meta) 开发的专门用于量化神经网络计算的加速库,其卓越的性能表现一经开源就击败了几乎全部已公开的加速算法。到目前为止,QNNPACK 仍然是已公开的,用于移动端(手机)的,性能最优的量化神经网络加速库。本节将会深入介绍 QNNPACK 算法的实现过程。
前置知识回顾#
在介绍 QNNPACK 算法前,先回顾一下传统的矩阵卷积运算方法。
Im2Col 算法回顾#
简单的 1×1 卷积可以直接映射到矩阵-矩阵乘法,但对于具有较大内核、填充或下采样(步幅)的卷积,则不是这种情况。这些更复杂的卷积可以通过结合 Im2Col 算法与 GEMM 算法来实现:即将四维的输入图像按照卷积窗尺寸进行重排成为一个二维的矩阵,同时将卷积核进行展开重排也成为一个二维的矩阵,将卷积操作转换为两个矩阵的乘法,直接使用 GEMM 方式完成矩阵乘即可。Im2Col + GEMM 方法能成功的原因本质上是其拆解后忽略内存复用后的计算过程等价于矩阵乘。
现假设已经完成 Im2Col 的转换,将卷积已经转换为如下图所示的矩阵乘法。B 矩阵为 kernel,尺寸为 N × K;A 矩阵为 feature map,尺寸为 K × M;结果矩阵 C 尺寸为 N × M。要想得到 C 矩阵中某一个位置的数据,需要计算 B 矩阵中对应列与 A 矩阵中对应行相乘的结果。
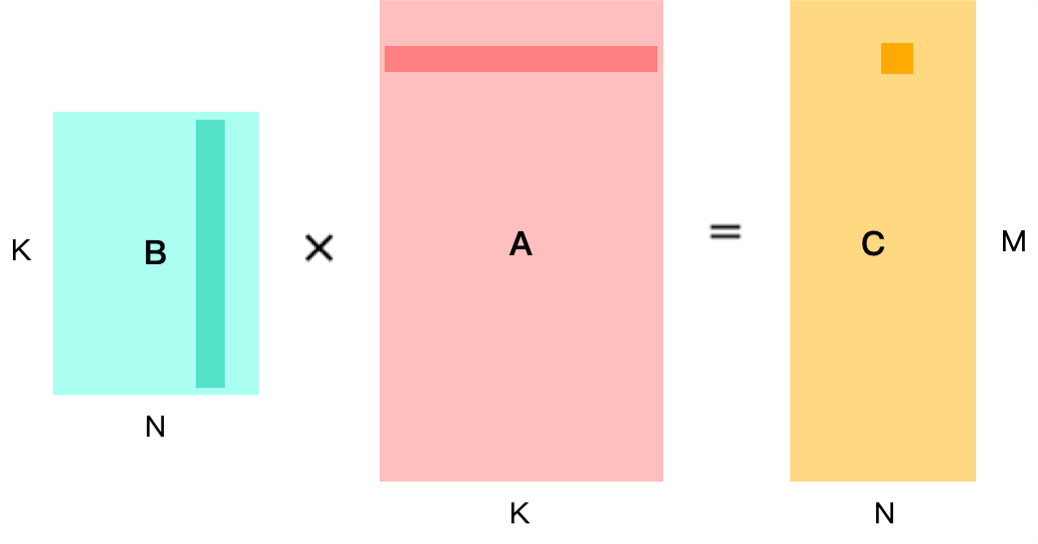
一般经过向量化优化后,同时可以并行计算多个结果数据,则一次计算一块 MR × NR 的小块。
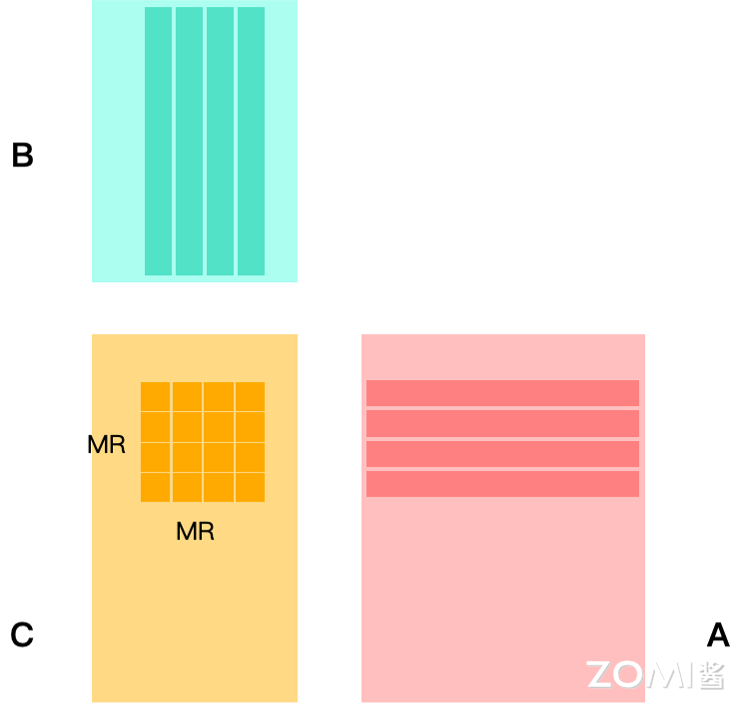
在分块概念出现后,传统 Im2Col+GEMM 方法一般是在 K 维度上进行拆分,在一次计算核中仅计算 K 维的局部,最后通过累加得到结果数据。这样的话,在每次计算核的处理中,都会发生对输出的加载和存储,即要将本次计算产生的部分和累加到输出中。
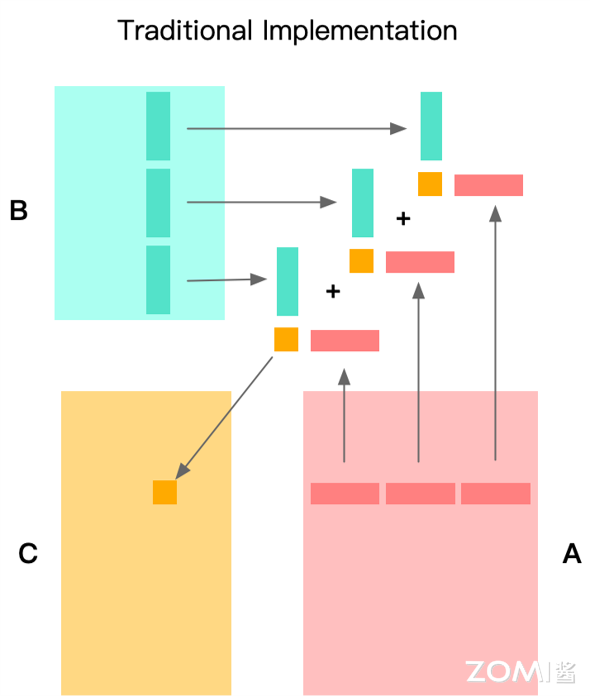
使用传统 Im2Col + GEMM 存在几个明显的缺陷:
Im2Col 消耗空间较大:使用 Im2Col 方法将输入图像以及卷积核展开成为二维中间矩阵会消耗大量内存空间。
GEMM 输入缓存空间较大:在面对大卷积核时,使用 GEMM 进行通用矩阵乘时需要缓存大量的行数据,就算采用分割方法同样不可避免。
针对以上缺陷,Marat Dukhan 提出的间接卷积算法(即 QNNPACK)都能较好地解决。
神经网络量化#
QNNPACK 原本推出的目的是解决量化问题,但后续发现在非量化的矩阵卷积运算中通用能发挥强大的性能。
神经网络的计算通常依赖于单精度浮点数(FP32)。然而,随着深度学习算法的不断发展,神经网络对计算资源和内存的需求急剧增加。这种需求的增加使得许多移动设备无法有效地运行复杂的神经网络模型。
为了解决这个问题,量化(Quantization)技术被引入到神经网络中。量化的核心思想是将神经网络中的权重参数和计算从 FP32 转换为低精度的整型数,例如 FP16/FP8/INT8。通过这种转换,计算速度和内存利用效率得到了显著提升。
线性量化的核心公式涉及 3 个参数:
缩放因子(Scale):将浮点数值缩放到整数值范围的比例。
零点(Zero Point):量化过程中用来调整数值的偏移量。
量化值(Quantized Value):最终的整数表示形式。
量化公式即可以表示如下:
给定一个浮点数 r 和相应的缩放因子 scale 和零点 zeropoint,量化过程可以表示为:
其中,q 是量化后的整数值,round() 表示四舍五入操作。
缩放因子与零点需要根据数据的范围(最大值和最小值)计算得到。
缩放因子的计算公式如下:
零点的计算公式如下。
在推理过程中,需要执行反量化过程,以便恢复接近原始的浮点表示。反量化过程的公式表达如下:
QNNPACK 使用一种与 Android 神经网络 API 兼容的线性量化方案。它假设量化值 q[i]用 8 位无符号整数表示,并且它们与实值表示 r[i]的关系如下公式:
其中,scale 是一个正的浮点数,zeropoint 是一个 8 位无符号整数,和 q[i]一样。
QNNPack 算法#
Marat Dukhan 于 2019 年离开 Meta 来到谷歌之后,发表了一篇名为 The Indirect Convolution Algorithm 的文章,揭秘了 QNNPack 加速库中针对矩阵卷积运算的核心算法,即如文章标题所示的 The Indirect Convolution Algorithm(间接卷积算法)。
在本节中,将结合 The Indirect Convolution Algorithm 这篇论文以及 QNNPack 在开源时同期发布的一篇技术性博客 QNNPACK: Open source library for optimized mobile deep learning,带领大家领略间接卷积算法的魅力。
对计算进行划分#
虽然 QNNPACK 利用了像其他 BLAS 库一样的 PDOT 微内核,但其对具有 8 位元素的量化张量和移动 AI 使用案例的关注带来了非常不同的性能优化视角。大多数 BLAS 库针对科学计算使用案例,处理的矩阵通常由成千上万的双精度浮点元素组成,而 QNNPACK 的输入矩阵来自低精度、移动设备特定的计算机视觉模型,具有非常不同的维度。
PDOT:Parallel Dot Product,是一种专门用于加速矩阵乘法运算的小型计算核心,它在处理低精度整数如 8 位整数和矩阵乘法时表现出色,特别是在移动设备和资源受限的硬件环境中。
PDOT 微内核的设计目标是高效利用硬件资源,实现低精度整数矩阵乘法的高效计算。
移动架构的约束规定 MR 和 NR 不能超过 8。因此,即使在具有 1024 通道的最大模型中,PDOT 微内核中读取的整个内存块最多为 16KB,这甚至可以适应超低端移动核心的一级缓存。
这标志着 QNNPACK 与其他 GEMM 实现之间的重要区别:其他库会重新打包 A 和 B 矩阵,以更好地利用缓存层次结构,希望通过大量计算来摊销打包开销,而 QNNPACK 则针对 A 和 B 面板可以适应 L1 缓存的情况进行优化。因此,它旨在消除所有非计算必需的内存转换。
间接卷积算法的计算同样也是基于对输出的切分,计算 MR × NR 的小块。如图19.5.4所示,与传统 GEMM 方法不同的是,其将将整个 K 维全部在计算 Kernel 中处理完,消除了输出部分和的访存。这里所说的「将整个 K 维全部」并不是指 K 维不进行拆分,而是指拆分后不和其他维度交换,实际计算中 K 维会以 \(2^n\) 为基础进行拆分。
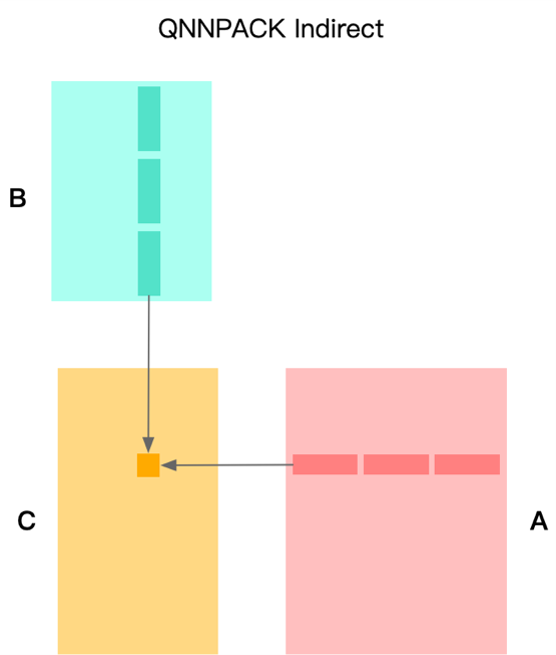
“消除所有非计算必需的内存转换”即为间接卷积算法的核心特定,这样的特性同样也注定了它在非量化任务中同样能起到显著的优化作用。
内存重排#
内存重排(repacking)是一种优化技术,旨在提高内存使用效率,减少内存碎片,提升程序性能。其核心思想是通过重新安排内存块的位置,使得内存的使用更加紧凑,减少不必要的内存开销。
一般情况下,内存碎片一般分为内部碎片与外部碎片。
内部碎片:分配的内存块比实际需要的要大,未使用的部分就形成了内部碎片。
外部碎片:在多次分配和释放内存后,内存中空闲的部分不能形成一个连续的可用内存块,从而无法满足大块内存分配需求。
内存重排的目的是通过紧凑化操作减少外部碎片,从而提升内存利用率。
一般的内存重排逻辑很简单,下面用一个例子来说明。
假设有一个内存空间,总大小为 \(M\),当前被使用的内存块为 \(B_1, B_2, \ldots, B_n\),每个内存块的大小分别为 \(S_1, S_2, \ldots, S_n\),它们的起始地址分别为 \(A_1, A_2, \ldots, A_n\)。
在内存重排后,我们希望所有内存块按顺序排列,新的起始地址分别为 \(A_1', A_2', \ldots, A_n'\),且需要消除内存块之间的空隙。那么,新的内存块起始地址需要满足以下关系:
\(A_{\text{base}}\) 是紧凑化后内存的起始地址,一般取 0。
为了计算每个内存块新的起始地址,使用如下公式:
上述公式的含义是第 i 个内存块的新起始地址等于前 i-1 个内存块大小总和。
现假设有如下内存块:
\(B_1\) 大小为 10,起始地址为 0。
\(B_2\) 大小为 20,起始地址为 20。
\(B_3\) 大小为 15,起始地址为 50。
经过内存紧凑化计算后,新的起始地址计算如下:
紧凑化后,内存布局改变为:
\(B_1\) 大小为 10,起始地址为 0。
\(B_2\) 大小为 20,起始地址为 10。
\(B_3\) 大小为 15,起始地址为 30。
内存紧凑化可以通过多种方式实现,下面展示一种常用的方式。此方式共分为三个阶段,一阶段为标记阶段,标记所有正在使用的内存块;二阶段为压缩阶段,将所有标记的内存块移动到内存的低地址部分;三阶段为更新引用阶段,更新所有指向移动内存块的指针。一个伪代码实现方式展示如下。
# 标记阶段
for each block in memory:
if block is in use:
mark(block)
# 压缩阶段
new_address = 0
for each block in memory:
if block is marked:
move(block, new_address)
new_address += block.size
# 更新引用
for each pointer in program:
if pointer points to a moved block:
update(pointer)
现结合卷积运算进行具体分析。在传统情况下,由于特征图尺寸可能很大,需要对输入内存进行重新组织,防止相邻的访存引起高速缓存冲突,但是这样的操作是需要额外开销的,具体来讲一般分为以下两种情况:
矩阵 A 的 Repacking:由于矩阵 A 包含卷积输入数据,并且每次推理运行时都会改变,因此每次运行都需要重打包,这会导致额外的开销。
矩阵 B 的 Repacking:矩阵 B 包含静态权重,可以一次性地转换为任何内存布局,这样在后续计算中可以更高效地使用缓存。
QNNPACK 通过消除不必要的 Repacking,优化了内存使用率并提高计算效率。具体来讲通过如下几个方面来实现。
充分利用缓存:由于 QNNPACK 适配的是移动设备量化神经网络,K 一般来说较小,A 和 B 的面板总能装入 L1 缓存中,因此不需要像传统实现那样对 A 和 B 的面板进行分割和 Repacking。
消除 A 的 Repacking:由于 A 的数据在每次推理运行时都变化,传统实现为了提高缓存利用率和微内核效率会 Repacking A。但是,QNNPACK 通过确保整个面板适合 L1 缓存,避免了这种 Repacking,节省了每次运行的开销。
避免缓存关联性问题:传统实现中的 Repacking 部分是为了避免缓存关联性问题,即如果读取的行被大步长分隔,可能会导致不同行的元素落入同一缓存集合中,导致性能下降。而 QNNPACK 通过确保面板适合 L1 缓存,避免了这种情况。
间接缓冲区#
在 QNNPACK 中,Marat Dukhan 实现了一种更高效的算法。与其将卷积输入转换以适应矩阵-矩阵乘法的实现,不如调整微内核的实现,使其能够实时进行 Im2Col 转换。间接卷积算法的有效工作以来一个关键的前提——网络连续运行时,输入张量的内存地址保持不变。这一特性其实比较容易满足,即使地址真的需要变化,也可以将其拷贝到固定的内存区域中。
间接卷积算法没有将实际数据从输入张量复制到 Im2Col 缓冲区,而是设置了一个间接缓冲区(Indirection Buffer),其中包含指向用于计算每个输出像素的输入像素行的指针。同时,此算法还修改了矩阵-矩阵乘法微内核,使其从间接缓冲区加载指向虚拟矩阵 A 行的指针,这个缓冲区通常比 Im2Col 缓冲区小得多。
此外,如果输入张量的内存位置在推理运行之间不变,间接缓冲区可以在初始化时设置一次指向输入行的指针,然后在多个推理运行中重复使用。从实验结果可以观察到,使用间接缓冲区的微内核不仅消除了 Im2Col 转换的开销,而且性能稍微优于矩阵-矩阵乘法微内核(这可能是因为在计算不同的输出像素时重复使用了输入行)。
间接缓冲区是一个指向输入像素行的指针缓冲区。每行包含 C 个像素,并且这些行可以选择性地跨步。对于每个输出像素位置和每个内核元素,间接缓冲区包含一个指向输入像素行的指针,该行的像素将与相应内核元素的滤波器权重行进行卷积,以生成相应的输出像素。对于非单位内核的卷积,通常使用隐式填充。在带有隐式填充的卷积中,在计算卷积之前,输入张量在空间维度上被隐式地用零填充。
为了处理填充卷积,间接卷积算法需要一个显式的零向量——一个由 C 个元素初始化为零的常量向量。显式零向量不需要与输入张量连续,并且可以在多个卷积操作之间共享。在初始化间接缓冲区时,超出输入张量范围的输入行的指针将被替换为指向显式零向量的指针。
间接缓冲区依赖于多个参数:输入、输出和滤波器张量的形状,卷积步幅、扩张和隐式填充,以及指向输入张量和显式零张量的指针,以及输入张量中像素行的步幅。这些参数可以根据其变化频率及其对间接缓冲区的影响分为几类:
卷积步幅、扩张、内核大小、隐式填充、输入通道数和输出通道数:这些是神经网络模型的参数,一旦模型实例化后,它们实际上是不可变的。
输入或输出张量的高度和宽度:这些输入参数的变化需要完全重新初始化间接缓冲区。然而,对于大多数类型的模型,特别是在生产环境中,这种变化是罕见的。
批量大小:批量大小的变化仅需要对先前未初始化的批次索引部分重新初始化间接缓冲区。
输入张量或显式零向量的指针:这些输入参数的变化需要完全重新初始化间接缓冲区。为了避免这种开销,实现卷积的高级框架可以保证在没有形状变化的情况下,张量具有持久位置。
下图展示了间接卷积算法使用间接缓冲区执行卷积运算的基本工作流程:
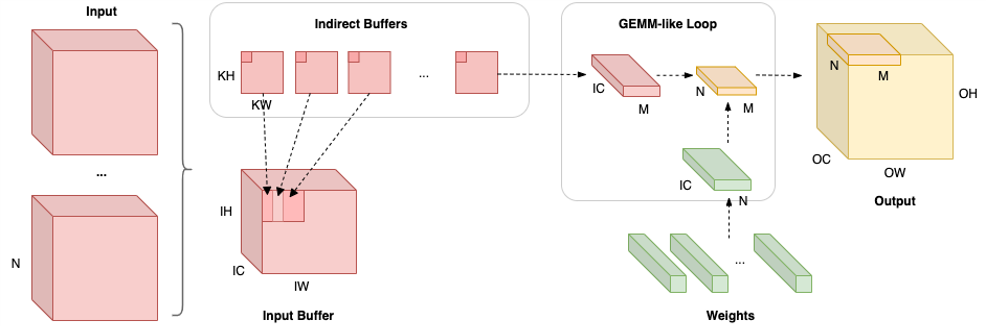
左侧部分表示多个输入使用相同的输入缓冲区(Input Buffer),间接卷积算法会在该输入缓冲区基础上构建间接缓冲区。如图中右侧在网络运行时,每次计算出 M × N 规模的输出,其中 M 将视为 OH × OW 视作一维后的向量规模化。一般 M × N 的尺寸在量化神经网络中是 4 × 4、4 × 8 以及 8 × 8。在计算 M×N 规模大小输出时,经由间接缓冲区取出对应输入缓冲区数据,并取出权重,计算出结果,整体计算过程等价于计算 M×K 和 K×N 矩阵乘。
在实现过程中,软件的执行过程分为两部分:
在准备阶段,需要执行加载模型配置输入缓冲区以及重排权重使其内存布局适用于后续计算两个工作。
在运行阶段,对于每个输入执行 (𝑂𝐻∗𝑂𝑊/𝑀)∗(𝑂𝐶/𝑁) 次循环,每次使用 GEMM 计算 𝑀×𝑁 大小输出。
间接缓冲区布局#
间接缓冲区可以理解为一组卷积核大小的缓冲区,共有 𝑂𝐻×𝑂𝑊 个,每个缓冲区大小为 𝐾𝐻×𝐾𝑊 (每个缓冲区对应某个输出要使用的输入地址)。每计算一个空间位置输出,使用一个间接缓冲区;空间位置相同而通道不同的输出使用相同间接缓冲区,缓冲区中的每个指针用于索引输入中 IC 个元素。
在计算时,随着输出的索引内存地址移动,选用不同的间接缓冲区,即可得到相应的输入地址。无需再根据输出目标的坐标计算要使用的输入的地址,这等同于预先计算地址。
下图以 M 和 N 均为 4,KH 和 KW 均为 3 的情况做出示例。
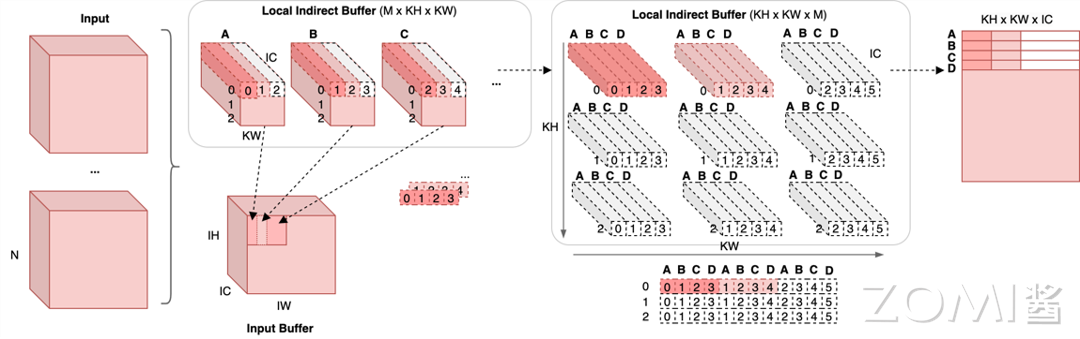
当计算大小为 M × N 大小的输出时,使用的输入为卷积核在对应输入位置上滑动 M 步所覆盖的区域,输入规模为:
这些输入内存由 M 个间接缓冲区中的指针索引,共有 M × KH × KW 个。
在上图左上部分标识出了输入空间位置与相应输入缓冲区的对应关系。可以看到,图中标出 A、B、C 共 3 个缓冲区,相邻的两个缓冲区所指向的地址有(KW - Stride)/KW 即 2/3 的区域相同。
图中将平面缓冲区展示为三维的形式(引入 IC 维度),意在说明间接缓冲区的每个指针可索引 IC 个输入元素,而每个间接缓冲区索引的内容即为与权重对应的输入内存区域。
进一步地,上图左上部分的输入缓冲区排列方式并不是最终排布方法,实际上这些指针会被处理成上图中部间接缓冲区的形式。将左上每个缓冲区中的指针打散,即可得到 KH × KW 指针,将 A、B、C 三个缓冲区的不同空间位置指针收集到一起,即可得到上图中上部分的缓冲区排列方式 KH × KW × M。
上图中上部分是可视化效果,间接缓冲区真正的组织方式如上图中下部分所示。A、B、C、D 四个缓冲区内部相同空间位置的指针被组织到了一起并横向排布。值得注意的是,图例中 Stride 为 1,当 Stride 不为 1 时,重新组织后 A、B、C、D 相同空间的坐标(对应于在输入的坐标)不一定是连续的,相邻的空间位置横向坐标相差 strdie 大小。
间接缓冲区计算#
现在来分析如何使用间接缓冲区完成计算。
和上一小节相同,本节讨论的依然为 M × N 规模的输出,而这些输出要使用 M 个 KH × KW 大小的输入,其中有数据重用。
卷积之所以可以使用 Im2col 优化算法,本质原因在于其拆解后忽略内存复用后的计算过程等价于矩阵乘。
间接缓冲区使得可以通过指针模拟出对输入的访存。在实际运行计算尺寸为 M × N 的计算核时,会有 M 个智障扫描输入。M 个指针每次从间接缓冲区中取出 M 个地址,即对应于 M × IC 的输入内存。指针以 M × S 的形式运行,其中 S 在 IC 维度上运动。此部分输入扫描完毕后,这 M 个指针从间接缓冲区中继续取出相应部分的指针,继续对下一轮 M × IC 输入内存进行遍历,每次计算出输出部分的大小为 1/(KH × KW)。当这个过程运行 KH × KW 次后即得到了 M × N 的输出。这一部分的操作可以用下面的伪代码表示出来。
for (int kh = 0; kh < KH; kh++){
for (int kw = 0; kw < KW; kw++){
dtype* pA = *(p_indirect_buffer++);
dtype* pB = *(p_indirect_buffer++);
dtype* pC = *(p_indirect_buffer++);
dtype* pD = *(p_indirect_buffer++);
for (int ic = 0; ic < IC; ic++){
o_A += *(pA++) * weight(...);
o_B += *(pB++) * weight(...);
o_C += *(pC++) * weight(...);
o_D += *(pD++) * weight(...);
}
}
}
由于间接缓冲区已经被组织成了特定的形状,因此每次更新 M 个指针时,只需要从间接缓冲区指针(伪代码中 p_indirect_buffer)中获取。
上述 M 个指针不断运动扫描的过程其实就是在扫描三维输入经过 Im2Col 之后的矩阵,而输入缓冲区的特点就是他将对二维矩阵的扫描转为对三维张量的扫描。上述 M × IC 的内存块其实是由 M 个 1 × IC 张量组成,他们之间 W 维度的间距为步长 stride。这样一来,只需要运行
次计算核,即可得到全部的输出。
与 Im2Col 算法对比#
与基于 Im2Col 的卷积算法相比,间接卷积的性能受到四个因素的影响:
消除非单位卷积的 Im2Col 转换。间接卷积方法不需要执行 Im2Col 转换,这减少了内存和计算开销,因为无需将输入数据块复制到 Im2Col 缓冲区。
改进的输入行缓存。对于大内核卷积,间接卷积方法通过从同一位置读取不同输出像素的输入行,提高了缓存效率。这是因为间接 GEMM 方法可以更好地利用缓存,而传统 GEMM 方法则需要从 Im2Col 缓冲区的不同位置读取数据,增加了缓存未命中率。
指针加载的开销。间接缓冲区引入了缓冲区指针,需要从间接缓冲区加载输入数据行的指针,这比在常量步幅假设下直接计算这些指针略微增加了开销。
循环效率的差异。间接卷积操作中,R × S(内核的高度和宽度)和 C(通道数)的迭代通过两个嵌套循环进行,这可能比 GEMM 操作中的单个循环(R × S × C 次迭代)效率稍低。单循环通常能更好地利用处理器的流水线和指令缓存,从而提高执行效率。
总体来说,间接卷积优化算法解决了卷积计算的三个问题,一是空间向量化问题,二是地址计算复杂问题,三是内存拷贝问题。同时间接卷积算法也存在一定的缺陷,即其建立的缓冲区和数据重新组织(Repacking)对内存造成大量的消耗。
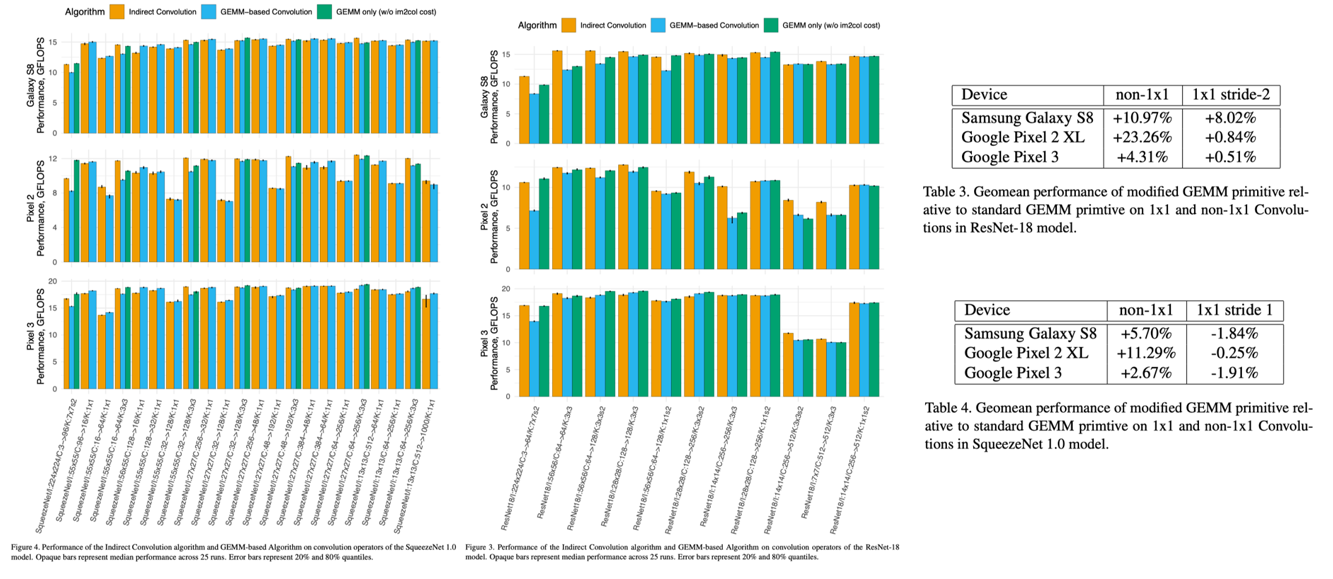
在 The Indirect Convolution Algorithm 中作者展示了间接卷积算法、基于 GEMM 的算法以及 ResNet18 和 SqueezeNet 1.0 模型中仅 GEMM 部分的性能。可以看到间接卷积算法性能会明显优于其他算法的性能。
小结与思考#
QNNPACK 是一种为量化神经网络设计的加速库,通过间接卷积算法优化移动设备上的计算性能。
QNNPACK 利用量化技术减少模型大小和内存需求,同时通过避免不必要的内存转换和优化内存访问模式提升效率。
QNNPACK 的间接卷积算法通过使用间接缓冲区和 PDOT 微内核,有效解决了传统卷积运算中的内存消耗和缓存效率问题。