GPU 工作原理#
前面的章节对 AI 计算体系和 AI 芯片基础进行讲解,在 AI 芯片基础中关于通用图形处理器 GPU 只是简单地讲解了主要概念,将从 GPU 硬件基础和英伟达 GPU 架构两个方面讲解 GPU 的工作原理。英伟达 GPU 有着很长的发展历史,整体架构从 Fermi 到 Blackwell 架构演变了非常多代,其中和 AI 特别相关的就有 Tensor Core 和 NVLink。
本节首先讲解 CPU 和 GPU 架构的区别,之后以 \(AX+Y\) 这个例子来探究 GPU 是如何做并行计算的,为了更好地了解 GPU 并行计算,对并发和并行这两个概念进行了区分。此外会讲解 GPU 的缓存机制,因为这将涉及到 GPU 的缓存(Cache)和线程(Thread)。
CPU vs GPU#
在正式开始内容之前,首先明确什么是 GPU ,以及 GPU 和 CPU 的主要区别是什么?
现在探讨一下 CPU 和 GPU 在架构方面的主要区别,CPU 即中央处理单元(Central Processing Unit),负责处理操作系统和应用程序运行所需的各类计算任务,需要很强的通用性来处理各种不同的数据类型,同时逻辑判断又会引入大量的分支跳转和中断的处理,使得 CPU 的内部结构异常复杂。
GPU 即图形处理单元(Graphics Processing Unit),可以更高效地处理并行运行时复杂的数学运算,最初用于处理游戏和动画中的图形渲染任务,现在的用途已远超于此。两者具有相似的内部组件,包括核心、内存和控制单元。
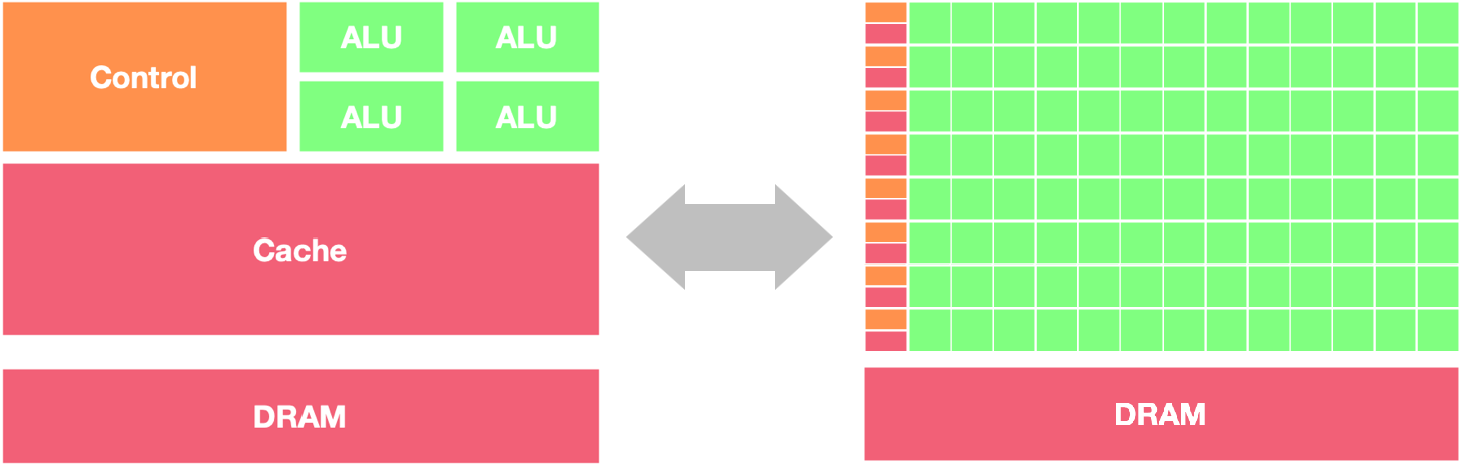
GPU 和 CPU 在架构方面的主要区别包括以下几点:
并行处理能力:CPU 拥有少量的强大计算单元(ALU),更适合处理顺序执行的任务,可以在很少的时钟周期内完成算术运算,时钟周期的频率很高,复杂的控制逻辑单元(Control)可以在程序有多个分支的情况下提供分支预测能力,因此 CPU 擅长逻辑控制和串行计算,流水线技术通过多个部件并行工作来缩短程序执行时间。GPU 控制单元可以把多个访问合并,采用了数量众多的计算单元(ALU)和线程(Thread),大量的 ALU 可以实现非常大的计算吞吐量,超配的线程可以很好地平衡内存延时问题,因此可以同时处理多个任务,专注于大规模高度并行的计算任务。
内存架构:CPU 被缓存 Cache 占据了大量空间,大量缓存可以保存之后可能需要访问的数据,可以降低延时。GPU 缓存很少且为线程(Thread)服务,如果很多线程需要访问一个相同的数据,缓存会合并这些访问之后再去访问 DRMA,获取数据之后由 Cache 分发到数据对应的线程。GPU 更多的寄存器可以支持大量 Thread。
指令集:CPU 的指令集更加通用,适合执行各种类型的任务。GPU 的指令集主要用于图形处理和通用计算。CPU 可以在不同的指令集之间快速切换,而 GPU 只是获取大量相同的指令并高速进行推送。
功耗和散热:CPU 的功耗相对较低,散热要求也相对较低。由于 GPU 的高度并行特性,其功耗通常较高,需要更好的散热系统来保持稳定运行。
因此,CPU 更适合处理顺序执行的任务,如操作系统、数据分析等;而 GPU 适合处理需要大规模并行计算的任务,如图形处理、深度学习等。在异构系统中,GPU 和 CPU 经常会结合使用,以发挥各自的优势。
GPU 起初用于处理图形图像和视频编解码相关的工作。GPU 跟 CPU 最大的不同点在于,GPU 的设计目标是最大化吞吐量(Throughput),相比执行单个任务的快慢,更关心多个任务的并行度(Parallelism),即同时可以执行多少任务;CPU 则更关心延迟(Latency)和并发(Concurrency)。
CPU 优化的目标是尽可能快地在尽可能低的延迟下执行完成任务,同时保持在任务之间具体快速切换的能力。它的本质是以序列化的方式处理任务。GPU 的优化则全部都是用于增大吞吐量的,它允许一次将尽可能多的任务推送到 GPU 内部,然后 GPU 通过大数量的 Core 并行处理任务。
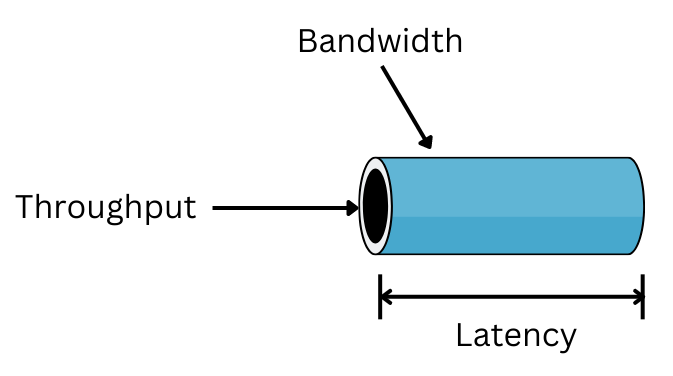
处理器带宽(Bandwidth)、延时(Lantency)和吞吐(Throughput)
带宽:处理器能够处理的最大的数据量或指令数量,单位是 Kb、Mb、Gb;
延时:处理器执行指令或处理数据所需的时间,传送一个数据单元所需要的时间,单位是 ms、s、min、h 等;
吞吐:处理器在一定时间内从一个位置移动到另一个位置的数据量,单位是 bps(每秒比特数)、Mbps(每秒兆比特数)、Gbps(每秒千比特数),比如在第 10s 传输了 20 bit 数据,因此在 t=10 时刻的吞吐量为 20 bps。
解决带宽相比较解决延时更容易,线程的数量与吞吐量成正比,吞吐量几乎等于带宽时说明信道使用率很高,处理器系统设计所追求的目标是提高带宽的前提下,尽可能掩盖传送延时,组成一个可实现的处理器系统。
并发与并行#
并行和并发是两个在计算机科学领域经常被讨论的概念,它们都涉及到同时处理多个任务的能力,但在具体含义和应用上有一些区别。
并行(Parallelism)
并行指的是同时执行多个任务或操作,通常是在多个处理单元上同时进行。在计算机系统中,这些处理单元可以是多核处理器、多线程、分布式系统等。并行计算可以显著提高系统的性能和效率,特别是在需要处理大量数据或复杂计算的情况下。例如,一个计算机程序可以同时在多个处理器核心上运行,加快整体计算速度。
并发(Concurrency)
并发指的是系统能够同时处理多个任务或操作,但不一定是同时执行。在并发系统中,任务之间可能会交替执行,通过时间片轮转或事件驱动等方式来实现。并发通常用于提高系统的响应能力和资源利用率,特别是在需要处理大量短时间任务的情况下。例如,一个 Web 服务器可以同时处理多个客户端请求,通过并发处理来提高系统的吞吐量。
因此并行和并发的主要区别如下:
并行是指同时执行多个任务,强调同时性和并行处理能力,常用于提高计算性能和效率。
并发是指系统能够同时处理多个任务,强调任务之间的交替执行和资源共享,常用于提高系统的响应能力和资源利用率。
在实际应用中,并行和并发通常结合使用,根据具体需求和系统特点来选择合适的技术和策略。同时,理解并行和并发的概念有助于设计和优化复杂的计算机系统和应用程序。在实际硬件工作的过程当中,更倾向于利用多线程对循环展开来提高整体硬件的利用率,这就是 GPU 的最主要的原理。
以三款芯片为例,对比在硬件限制的情况下,一般能够执行多少个线程,对比结果增加了线程的请求(Threads required)、线程的可用数(Threads available)和线程的比例(Thread Ration),主要对比到底需要多少线程才能够解决内存时延的问题。从表中可以看到几个关键的数据:
GPU(英伟达 A100)的时延比 CPU (AMD Rome 7742,Intel Xeon 8280)高出好几个倍数;
GPU 的线程数是 CPU 的二三十倍;
GPU 的可用线程数量是 CPU 的一百多倍。计算得出线程的比例,GPU 是 5.6,CPU 是 1.2~1.3,这也是 GPU 最重要的一个设计点,它拥有非常多的线程为大规模任务并行去设计。
AMD Rome 7742 |
Intel Xeon 8280 |
NVIDIA A100 |
|
|---|---|---|---|
Memory B/W(GB/sec) |
204 |
143 |
1555 |
DRAM Latency(ns) |
122 |
89 |
404 |
Peak bytes per latency |
24,888 |
12,727 |
628,220 |
Memory Efficiency |
0.064% |
0.13% |
0.0025% |
Threads required |
1,556 |
729 |
39,264 |
Threads available |
2048 |
896 |
221,184 |
Thread Ration |
1.3X |
1.2X |
5.6X |
CPU 和 GPU 的典型架构对比可知 GPU 可以比作一个大型的吞吐器,一部分线程用于等待数据,一部分线程等待被激活去计算,有一部分线程正在计算的过程中。GPU 的硬件设计工程师将所有的硬件资源都投入到增加更多的线程,而不是想办法减少数据搬运的延迟,指令执行的延迟。
相对应的可以把 CPU 比喻成一台延迟机,主要工作是为了在一个线程里完成所有的工作,因为希望能够使用足够的线程去解决延迟的问题,所以 CPU 的硬件设计者或者硬件设计架构师就会把所有的资源和重心都投入到减少延迟上面,因此 CPU 的线程比只有一点多倍,这也是 SIMD(Single Instruction, Multiple Data)和 SIMT(Single Instruction, Multiple Threads)架构之间最大的区别。CPU 不是通过增加线程来去解决问题,而是使用相反的方式去优化线程的执行速率和效率,这就是 CPU 跟 GPU 之间最大的区别,也是它们的本质区别。

SIMD (Single Instruction, Multiple Data) 和 SIMT (Single Instruction, Multiple Threads)
SIMD 架构是指在同一时间内对多个数据执行相同的操作,适用于向量化运算。例如,对于一个包含多个元素的数组,SIMD 架构可以同时对所有元素执行相同的操作,从而提高计算效率。常见的 SIMD 架构包括 SSE (Streaming SIMD Extensions) 和 AVX (Advanced Vector Extensions)。
SIMT 架构是指在同一时间内执行多个线程,每个线程可以执行不同的指令,但是这些线程通常会执行相同的程序。这种架构通常用于 GPU (Graphics Processing Unit) 中的并行计算。CUDA (Compute Unified Device Architecture) 和 OpenCL 都是支持 SIMT 架构的编程模型。
SIMD 适用于数据并行计算,而 SIMT 适用于任务并行计算。在实际应用中,根据具体的计算需求和硬件环境选择合适的架构可以提高计算性能。
GPU 工作原理#
基本工作原理#
首先通过 \(AX+Y\) 这个加法运算的示例了解 GPU 的工作原理,\(AX+Y\) 的示例代码如下:
void demo(double alpha, double *x, double *y)
{
int n = 2000;
for (int i = 0; i < n; ++i)
{
y[i] = alpha * x[i] + y[i];
}
}
示例代码中包含 2 FLOPS 操作,分别是乘法(Multiply)和加法(Add),对于每一次计算操作都需要在内存中读取两个数据,\(x[i]\) 和 \(y[i]\),最后执行一个线性操作,存储到 \(y[i]\) 中,其中把加法和乘法融合在一起的操作也可以称作 FMA(Fused Multiply and Add)。
在 O(n) 的时间复杂度下,根据 n 的大小迭代计算 n 次,在 CPU 中串行地按指令顺序去执行 \(AX+Y\) 程序。以 Intel Xeon 8280 这款芯片为例,其内存带宽是 131 GB/s,内存的延时是 89 ns,这意味着 8280 芯片的峰值算力是在 89 ns 的时间内传输 11659 个字节(byte)数据。\(AX+Y\) 将在 89 ns 的时间内传输 16 字节(C/C++中 double 数据类型所占的内存空间是 8 bytes)数据,此时内存的利用率只有 0.14%(16/11659),存储总线有 99.86% 的时间处于空闲状态。
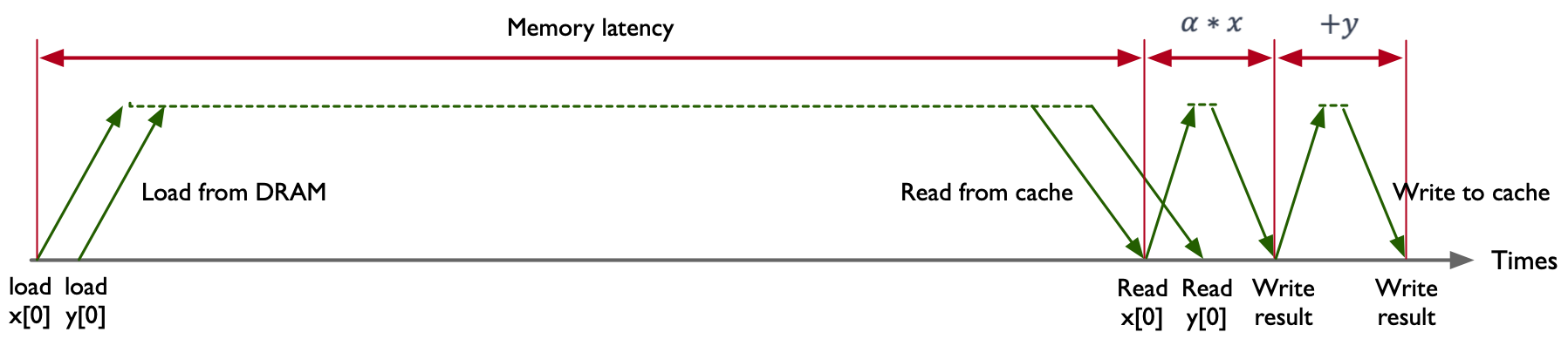
不同处理器计算 \(AX+Y\) 时的内存利用率,不管是 AMD Rome 7742、Intel Xeon 8280 还是英伟达 A100,对于 \(AX+Y\) 这段程序的内存利用率都非常低,基本 ≤0.14%。
AMD Rome 7742 |
Intel Xeon 8280 |
NVIDIA A100 |
|
|---|---|---|---|
Memory B/W(GB/sec) |
204 |
131 |
1555 |
DRAM Latency(ns) |
122 |
89 |
404 |
Peak bytes per latency |
24,888 |
11,659 |
628,220 |
Memory Efficiency |
0.064% |
0.14% |
0.0025% |
由于上面的 \(AX+Y\) 程序没有充分利用并发和线性度,因此通过并发进行循环展开的代码如下:
void fun_axy(int n, double alpha, double *x, double *y)
{
for (int i = 0; i < n; i += 8)
{
y[i + 0] = alpha * x[i + 0] + y[i + 0];
y[i + 1] = alpha * x[i + 1] + y[i + 1];
y[i + 2] = alpha * x[i + 2] + y[i + 2];
y[i + 3] = alpha * x[i + 3] + y[i + 3];
y[i + 4] = alpha * x[i + 4] + y[i + 4];
y[i + 5] = alpha * x[i + 5] + y[i + 5];
y[i + 6] = alpha * x[i + 6] + y[i + 6];
y[i + 7] = alpha * x[i + 7] + y[i + 7];
}
}
每次执行从 0 到 7 的数据,实现一次性迭代 8 次,每次传输 16 bytes 数据,因此同样在 Intel Xeon 8280 芯片上,每 89 ns 的时间内将执行 8 次请求,内存带宽的利用率就翻了 8 倍。现在,如果我们想要最大程度上的利用内存带宽,每 89 ns 的时间内我们最多可以执行 728(11659/16)次请求,将程序这样改进就是通过并发使整个总线处于一个忙碌的状态,但是在真正的应用场景中:
编译器很少会对整个循环进行超过 100 次以上的展开;
一个线程每一次执行的指令数量是有限的,不可能执行非常多并发的数量;
一个线程其实很难直接去处理 700 多个计算的负荷。
由此可以看出,虽然并发的操作能够一次性执行更多的指令流水线操作,但是同样架构也会受到限制和约束。
将 \(Z=AX+Y\) 通过并行进行展开,示例代码如下:
void fun_axy(int n, double alpha, double *x, double *y)
{
Parallel for (int i = 0; i < n; i++)
{
y[i] = alpha * x[i] + y[i];
}
}
通过并行的方式进行循环展开,并行就是通过并行处理器或者多个线程去执行 \(AX+Y\) 这个操作,同样使得总线处于忙碌的状态,每一次可以执行 728 个迭代。相比较并发的方式:
每个线程独立负责相关的运算,也就是每个线程去计算一次 \(AX+Y\);
执行 728 次计算一共需要 728 个线程,也就是一共可以进行 728 次并行计算;
此时程序会受到线程数量和内存请求的约束。
GPU 缓存机制#
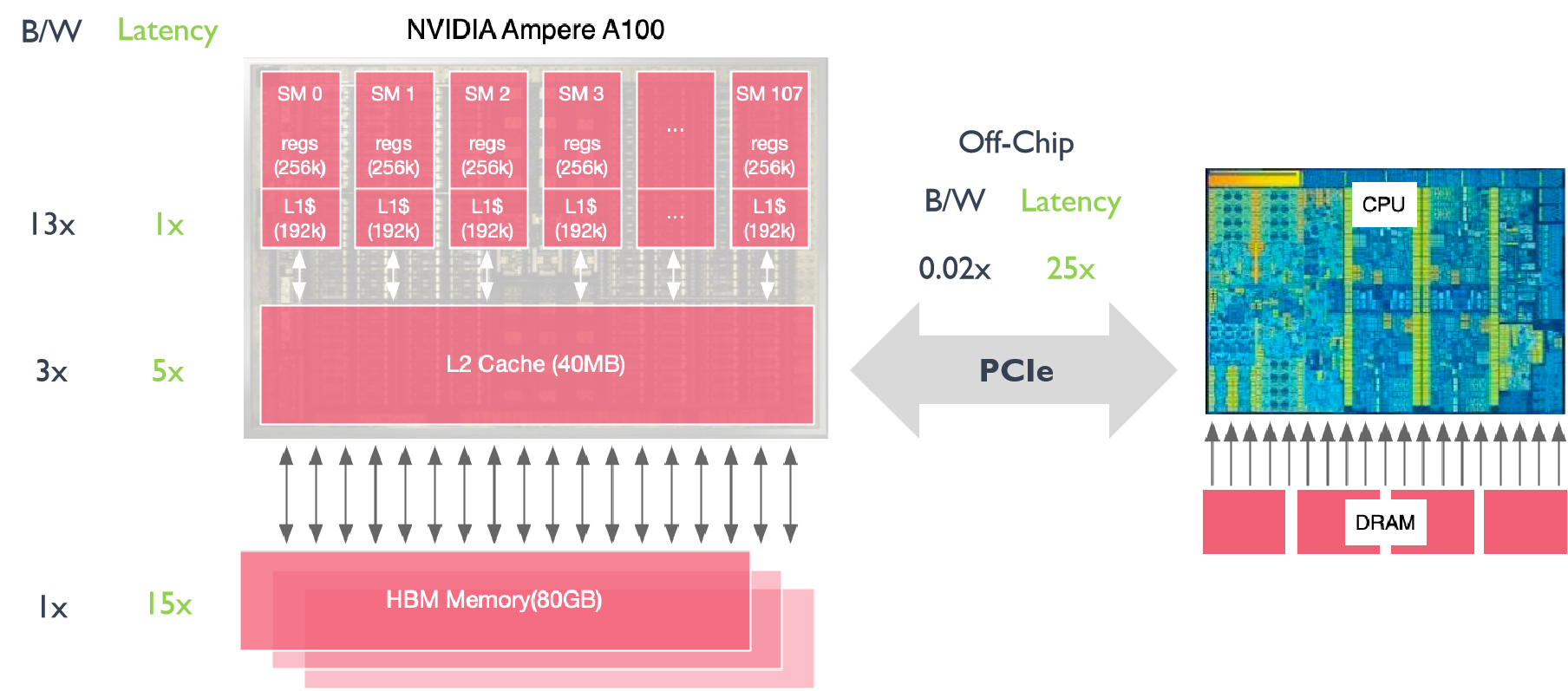
在 GPU 工作过程中希望尽可能的去减少内存的时延、内存的搬运、还有内存的带宽等一系列内存相关的问题,其中缓存对于内存尤为重要。英伟达 Ampere A100 内存结构中 HBM Memory 的大小是 80G,也就是 A100 的显存大小是 80G。
其中寄存器(Register)文件也可以视为缓存,寄存器靠近 SM(Streaming Multiprocessors)执行单元,从而可以快速地获取执行单元中的数据,同时也方便读取 L1 Cache 缓存中的数据。此外 L2 Cache 更靠近 HBM Memory,这样方便 GPU 把大量的数据直接搬运到 cache 中,因此为了同时实现上面两个目标,GPU 设计了多级缓存。80G 的显存是一个高带宽的内存,L2 Cache 大小为 40M,所有 SM 共享同一个 L2 Cache,L1 Cache 大小为 192kB,每个 SM 拥有自己独立的 Cache,同样每个 SM 拥有自己独立的 Register,每个寄存器大小为 256 kB,因为总共有 108 个 SM 流处理器,因此寄存器总共的大小是 27MB,L1 Cache 总共的大小是 20 MB。
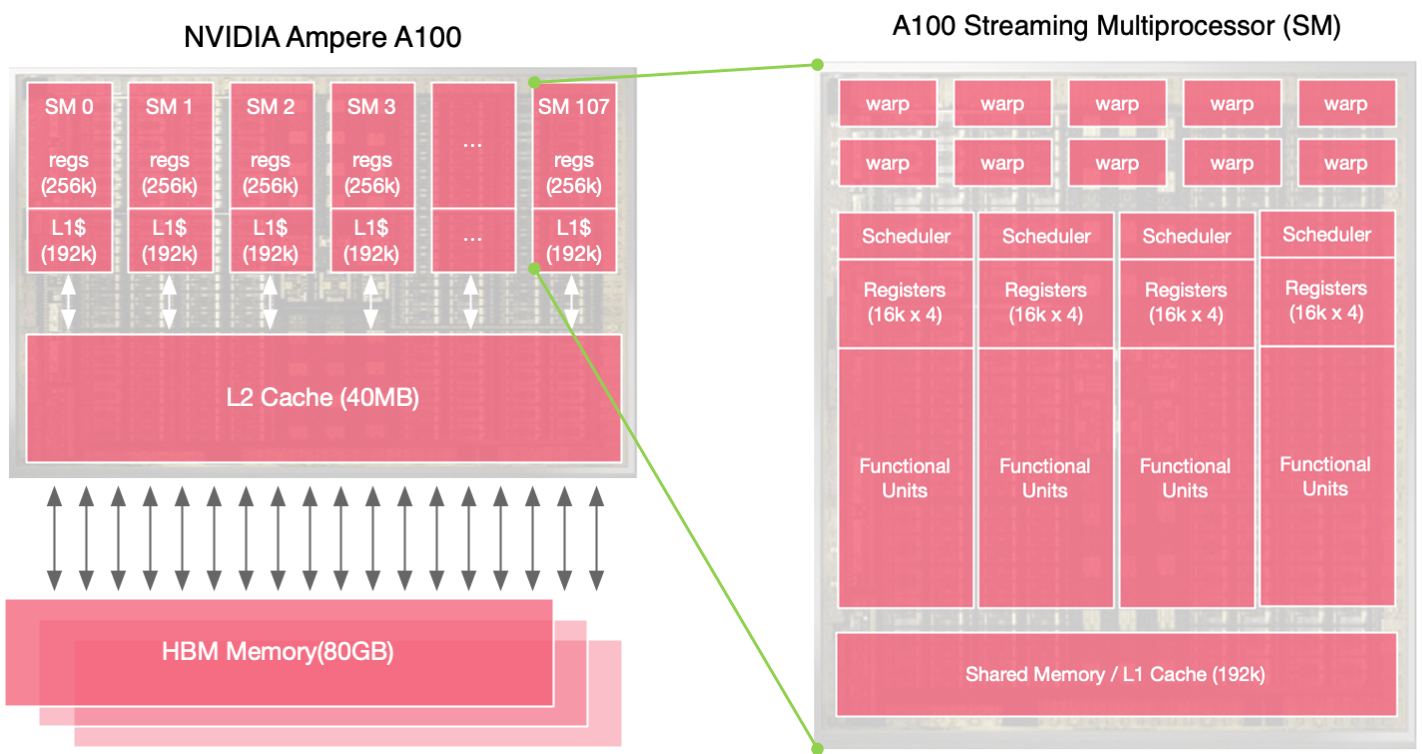
GPU 和 CPU 内存带宽和时延进行比较,在 GPU 中如果把主内存(HBM Memory)作为内存带宽(B/W, bandwidth)的基本单位,L2 缓存的带宽是主内存的 3 倍,L1 缓存的带宽是主存的 13 倍。在真正计算的时候,希望缓存的数据能够尽快的去用完,然后读取下一批数据,此时就会遇到时延(Lentency)的问题。如果将 L1 缓存的延迟作为基本单位,L2 缓存的延迟是 L1 的 5 倍,HBM 的延迟将是 L1 的 15 倍,因此 GPU 需要有单独的显存。
假设使用 CPU 将 DRAM(Dynamic Random Access Memory)中的数据传入到 GPU 中进行计算,较高的时延(25 倍)会导致数据传输的速度远小于计算的速度,因此需要 GPU 有自己的高带宽内存 HBM(High Bandwidth Memory),GPU 和 CPU 之间的通信和数据传输主要通过 PCIe 来进行。
DRAM 动态随机存取存储器(Dynamic Random Access Memory)
一种计算机内存类型,用于临时存储计算机程序和数据,以供中央处理器(CPU)快速访问。与静态随机存取存储器(SRAM)相比,具有较高的存储密度和较低的成本,但速度较慢。它是计算机系统中最常用的内存类型之一,用于存储操作系统、应用程序和用户数据等内容。
DRAM 的每个存储单元由一个电容和一个晶体管组成,电容负责存储数据位(0 或 1),晶体管用于读取和刷新数据。由于电容会逐渐失去电荷,因此需要定期刷新(称为刷新操作)以保持数据的正确性,这也是称为“动态”的原因,用于临时存储数据和程序,提供快速访问速度和相对较低的成本。
存储类型 |
结构 |
工作原理 |
性能 |
应用 |
|---|---|---|---|---|
DRAM(Dynamic Random Access Memory) |
一种基本的内存技术,通常以单层平面的方式组织,存储芯片分布在一个平面上 |
当读取数据时,电荷被传递到输出线路,然后被刷新。当写入数据时,电荷被存储在电容中。由于电容会逐渐失去电荷,因此需要周期性刷新来保持数据 |
具有较高的密度和相对较低的成本,但带宽和延迟相对较高 |
常用于个人电脑、笔记本电脑和普通服务器等一般计算设备中 |
GDDR(Graphics Double Data Rate) |
专门为图形处理器设计的内存技术,具有较高的带宽和性能 |
在数据传输速度和带宽方面优于传统的 DRAM,适用于图形渲染和视频处理等需要大量数据传输的应用 |
GDDR 与标准 DDR SDRAM 类似,但在设计上进行了优化以提供更高的数据传输速度。它采用双倍数据速率传输,即在每个时钟周期传输两次数据,提高了数据传输效率 |
主要用于高性能图形处理器(GPU)和游戏主机等需要高带宽内存的设备中 |
HBM(High Bandwidth Memory) |
使用堆叠设计,将多个 DRAM 存储芯片堆叠在一起,形成三维结构 |
堆叠设计允许更短的数据传输路径和更高的带宽,同时减少了功耗和延迟。每个存储芯片通过硅间连接(Through Silicon Via,TSV)与其他存储芯片通信,实现高效的数据传输 |
具有非常高的带宽和较低的延迟,适用于高性能计算和 AI 等需要大量数据传输的领域 |
主要用于高端图形处理器(GPU)、高性能计算系统和服务器等需要高带宽内存的设备中 |
不同存储和传输的带宽和计算强度进行比较,假设 HBM 计算强度为 100,L2 缓存的计算强度只为 39,意味着每个数据只需要执行 39 个操作,L1 的缓存更少,计算强度只需要 8 个操作,这个时候对于硬件来说非常容易实现。这就是为什么 L1 缓存、L2 缓存和寄存器对 GPU 来说如此重要。可以把数据放在 L1 缓存里面然后对数据进行 8 个操作,使得计算达到饱和的状态,使 GPU 里面 SM 的算力利用率更高。但是 PCIe 的带宽很低,整体的时延很高,这将导致整体的算力强度很高,算力利用率很低。
DataLocation |
Bandwidth(GB/sec) |
ComputeIntensity |
Latency(ns) |
Threads Required |
|---|---|---|---|---|
L1 Cache |
19,400 |
8 |
27 |
32,738 |
L2 Cache |
4,000 |
39 |
150 |
37,500 |
HBM |
1,555 |
100 |
404 |
39,264 |
NVLink |
300 |
520 |
700 |
13,125 |
PCIe |
25 |
6240 |
1470 |
2297 |
在带宽增加的同时线程的数量或者线程的请求数也需要相对应的增加,这个时候才能够处理并行的操作,每个线程执行一个对应的数据才能够把算力利用率提升上去,只有线程数足够多才能够让整个系统的内存处于忙碌的状态,让计算也处于忙碌的状态,因此看到 GPU 里面的线程数非常多。
GPU 线程原理#
GPU 整体架构和单个 SM(Streaming Multiprocessor)的架构,SM 可以看作是一个基本的运算单元,GPU 在一个时钟周期内可以执行多个 Warp,在一个 SM 里面有 64 个 Warp,其中每四个 Warp 可以单独进行并发的执行,GPU 的设计者主要是增加线程和增加 Warp 来解决或者掩盖延迟的问题,而不是去减少延迟的时间。
为了有更多的线程处理计算任务,GPU SMs 线程会选择超配,每个 SM 一共有 2048 个线程,整个 A100 有 20 多万个线程可以提供给程序,在实际场景中程序用不完所有线程,因此有一些线程处于计算的过程中,有一些线程负责搬运数据,还有一些线程在同步地等待下一次被计算。很多时候会看到 GPU 的算力利用率并不是非常的高,但是完全不觉得它慢是因为线程是超配的,远远超出大部分应用程序的使用范围,线程可以在不同的 Warp 上面进行调度。
Per SM |
A100 |
|
|---|---|---|
Total Threads |
2048 |
221,184 |
Total Warps |
64 |
6,912 |
Active Warps |
4 |
432 |
Waiting Warps |
60 |
6,480 |
Active Threads |
128 |
13,824 |
Waiting Threads |
1,920 |
207,360 |
小结与思考#
GPU 与 CPU 架构差异:GPU 拥有大量并行处理单元,专为吞吐量优化,适合执行大规模并行计算任务,而 CPU 设计有少量强大计算单元,优化以降低延迟,适合处理顺序执行任务。
GPU 并行计算原理:GPU 通过超配线程和 Warp(一组同时执行相同指令的线程)来掩盖内存延迟,利用其高吞吐量架构来提升性能,与 CPU 的低延迟设计形成对比。
GPU 缓存机制与线程原理:GPU 采用多级缓存结构来降低对主内存的依赖,并通过大量线程超配来提高算力利用率,其中 L1 Cache、L2 Cache 和寄存器的设计有助于提升数据传输和计算效率。