Im2Col 算法#
作为早期的 AI 框架,Caffe 中卷积的实现采用的是基于 Im2Col 的方法,至今仍是卷积重要的优化方法之一。
从上一节的介绍中可以看到,在 CNN 中卷积直接计算的定义中,卷积核在输入图片上滑动,对应位置的元素相乘后相加求和,滑窗的大小由卷积核决定。由于滑动操作时的窗口的数据横向是连续的,但是不同行在内存中是不连续的,在计算时有可能需要多次访问内存。由于多次访问内存直接增加了数据传输时间,从而进一步影响了卷积计算速度,这样就造成了整体效率低等问题。
Im2Col 是计算机视觉领域中将图片转换成矩阵的矩阵列的计算过程。Img2col 的作用就是将卷积通过矩阵乘法来计算,从而能在计算过程中将需要计算的特征子矩阵存放在连续的内存中,有利于一次将所需要计算的数据直接按照需要的格式取出进行计算,这样便减少了内存访问的次数,从而减小了计算的整体时间。
在 AI 框架发展的早期,Caffe 使用 Im2Col 方法将三维张量转换为二维矩阵,从而充分利用已经优化好的 GEMM 库来为各个平台加速卷积计算。最后,再将矩阵乘得到的二维矩阵结果使用 Col2Im 将转换为三维矩阵输出。其处理流程如下图所示。

数学原理#
Im2Col 算法的优化策略为用空间换时间,用连续的行向量的存储空间作为代价优化潜在的内存访问消耗的时间。其实施过程依据的是线性代数中最基本的矩阵运算的原理,根据上一节的特征图计算公式可得:
根据上述式子可知,每个窗口下对应的卷积计算和两个一维向量的点乘计算是等价的。由此可以推知,在未改变直接卷积计算的参数量和连接数的情况下,这种将每个窗口中的特征子矩阵展开成一维的行向量后再进行矩阵乘计算的思路,能够通过减少计算过程中的访存需求,优化整体的计算时间。
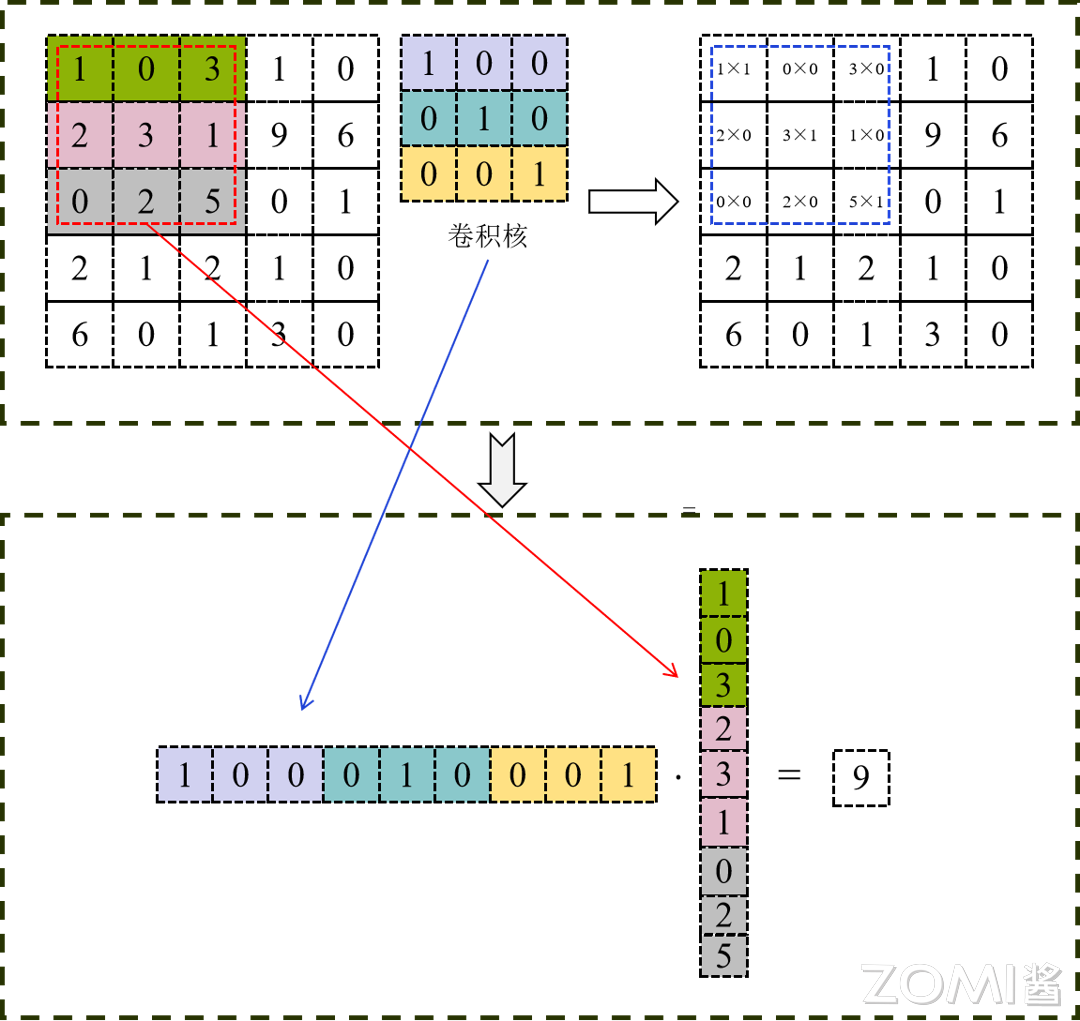
Im2Col 算法就是在这样的基础上进行设计的。其将卷积通过矩阵乘法来计算,最后调用高性能的 Matmul (矩阵乘法)进行计算。该方法适应性强,支持各种卷积参数的优化,在通道数稍大的卷积中性能基本与 Matmul 持平,并且可以与其他优化方法形成互补。
算法过程#
除非特别说明,本文默认采用的内存布局形式为 NHWC。其他的内存布局和具体的转换后的矩阵形状或许略有差异,但不影响算法本身的描述。
Im2Col+Matmul 方法主要包括两个步骤:
使用 Im2Col 将输入矩阵展开一个大矩阵,矩阵每一列表示卷积核需要的一个输入数据,按行向量方式存储。
使用上面转换的矩阵进行 Matmul 运算,得到的数据就是最终卷积计算的结果。
卷积过程#
一般图像的三通道卷积,其输入为 3 维张量 \((H, W, 3)\),其中 \(H\),\(W\) 为输入图像的高和宽,3 为图像的通道数;卷积核为 4 维张量 \((N, C, KH, KW)\),其中 \(N\) 为卷积核的个数,\(KH\),\(KW\) 为卷积核的高和宽,\(C\) 为卷积核的通道数,卷积核的通道数应与输入图像的通道数一致;输出为 3 维张量 \((N, H, W)\),其中 \(H\),\(W\) 为输入图像的高和宽,\(N\) 为输出图像的通道数,输出图的通道数应与卷积核个数一致。此段中 \(H,W\) 只是代指,并不表示数值通用,输出图像的宽高具体数值需要按照公式另行计算。其卷积的一般计算方式为:
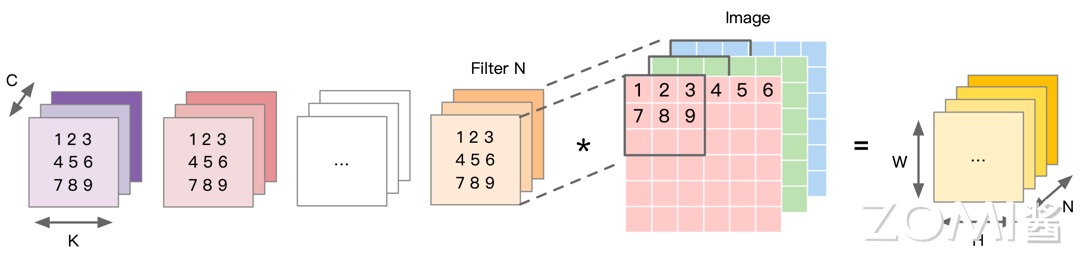
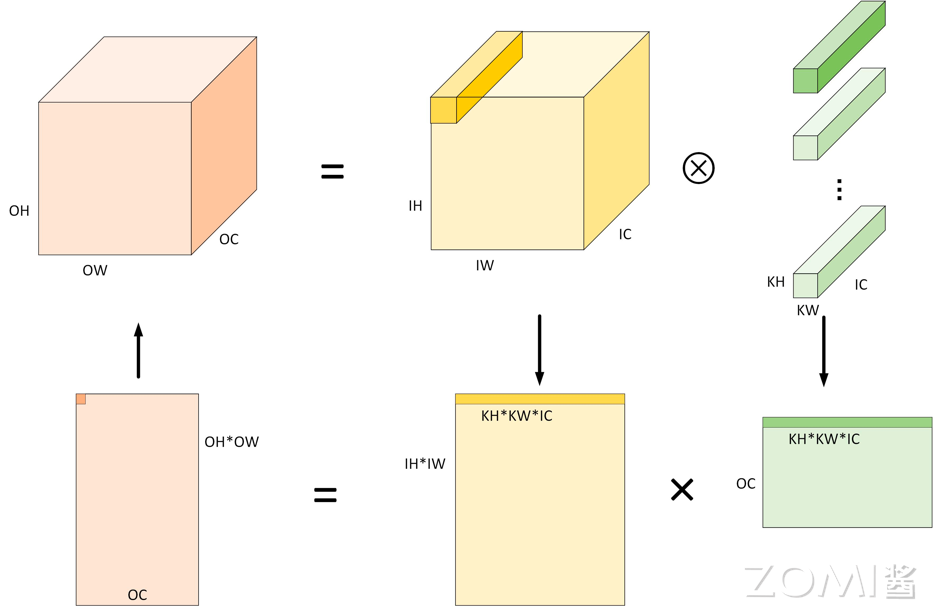
在神经网络中,卷积默认采用数据排布方式为 \(NHWC\),意为(样本数,高,宽,通道数)。输入图像/特征图为 4 维张量 \((N,IH,IW,IC)\),其中 \(N\) 为输入图像的个数,也可以理解为单次训练的样本数,\(IH\),\(IW\) 为输入图像的高和宽,\(IC\) 为通道数;卷积核为 4 维张量 \((OC,KH,KW,IC)\),卷积核的通道数应与输入图像的通道数一致,所以均为 \(IC\),这里的 \(OC\) 应与下图中卷积核个数 N 在数值上对应相等,表示卷积核的个数,其遵循一个卷积核计算得到一张特征图这样一一对应的规则。注意图中的 N 与输入图像的个数 \(N\) 并不相关,数值也不一致,图中的 N 表示卷积核个数。输出为 4 维张量 \((N,OH,OW,OC)\),这里的 \(N\) 等价于前述输入图像的个数,\(OC\) 表示输出特征图的个数,也就是每个样本卷积后的输出的通道数。卷积的一般计算方式为:
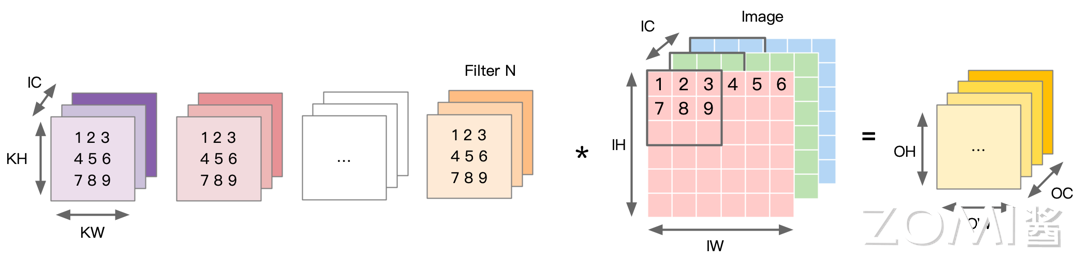
Im2Col 算法原理#
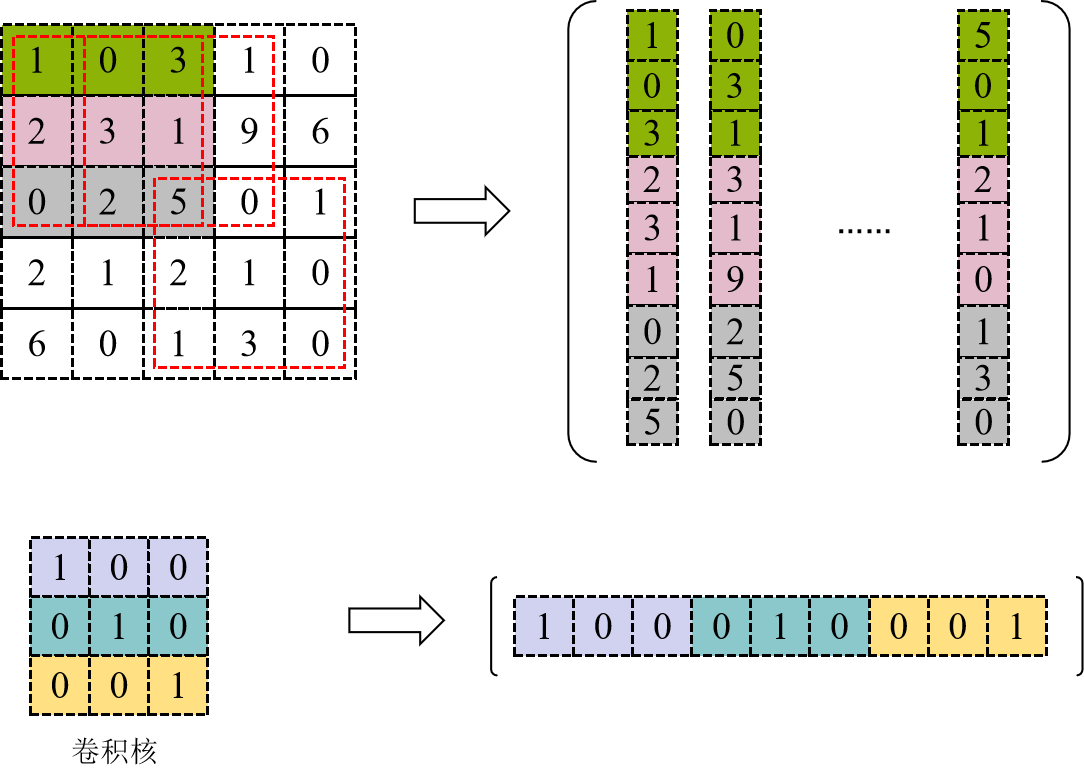
Im2Col 算法的核心是改变了数据在内存中的排列存储方式,将卷积操作转换为矩阵相乘,对 Kernel 和 Input 进行重新排列。将输入数据按照卷积窗进行展开并存储在矩阵的列中,多个输入通道的对应的窗展开之后将拼接成最终输出 Matrix 的一列。其过程如下图所示,卷积核被转化为一个 \(N×(KW*KH*C)\) 的二维矩阵,输入被转化为一个 \((KW*KH*C)×(OH*OW)\) 的矩阵,输入矩阵的列数由卷积核在输入图像上的滑动次数所决定,具体数值可由特征图的尺寸 \((OH*OW)\) 计算得到,这两个数值根据上一节特征图的公式进行计算。
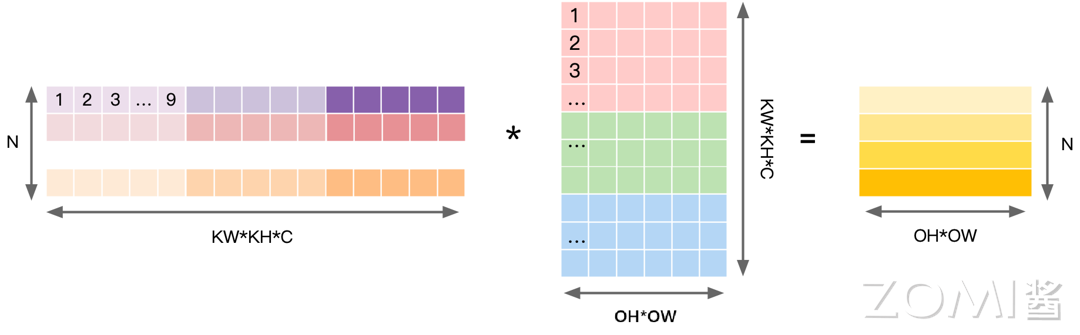
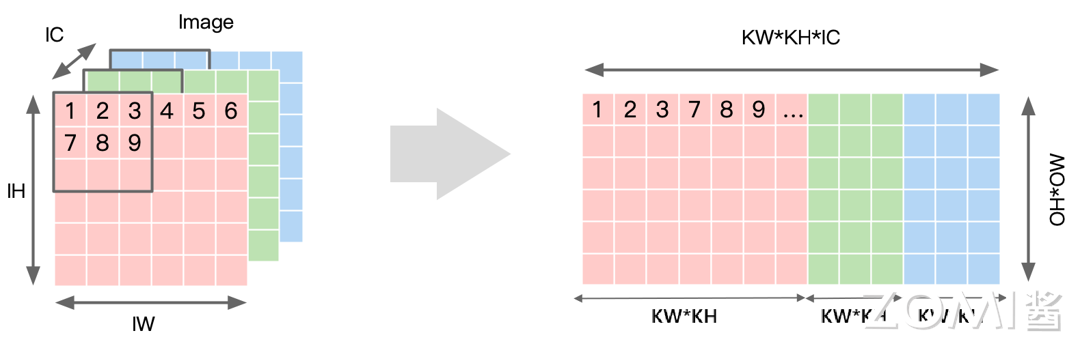
Input 重排
对 Input 进行重排,得到的矩阵见下图右侧,矩阵的行数对应输出 \(OH*OW\) 个数,也就是卷积核在 Input 上的滑动次数;每个行向量里,先排列计算一个输出点所需要输入上第一个通道的 \(KH*KW\) 个数据,根据卷积窗的大小逐行拼接成一段行向量,排完当前通道的数据后,以同样模式再按次序排列之后的通道的数据,直到第 \(IC\) 个通道,最终构成前述完整的一个行向量。
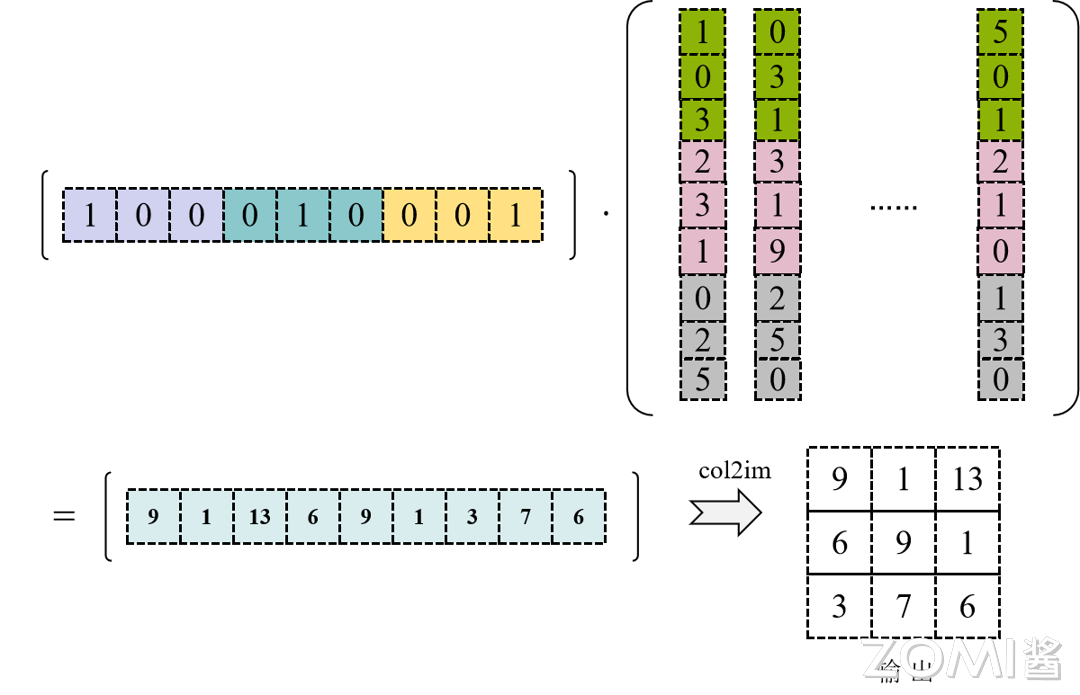
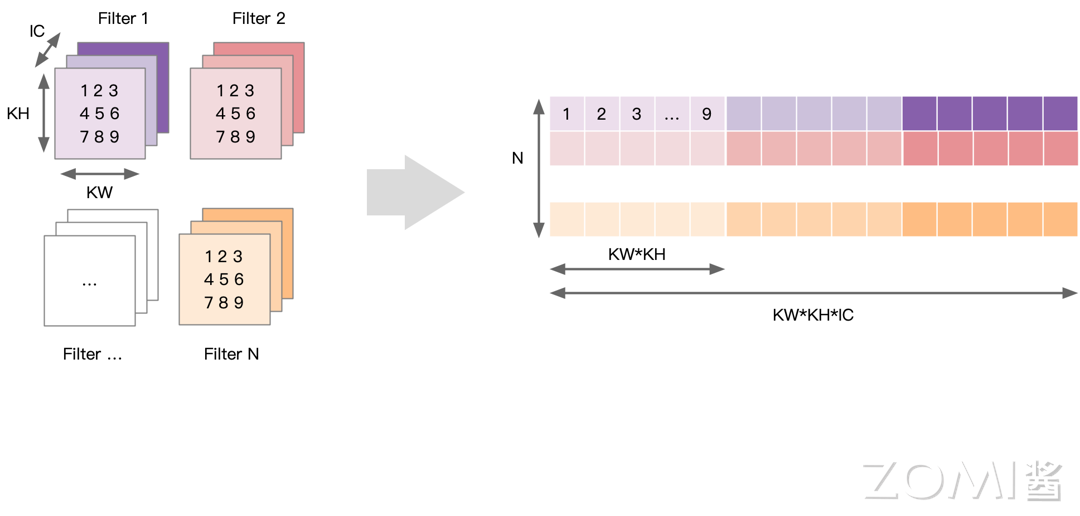
权重数据重排
对权重数据进行重排,将 \(N\) 个卷积核展开为权重矩阵的一行,因此共有 \(N\) 行,每个行向量上先排列第一个输入通道上 \(KH*KW\) 数据,根据卷积窗的大小逐行拼接成一段行向量,排完当前通道的数据后,以同样模式再依次排列后面的通道数据直到 \(IC\)。
通过数据重排,完成 Im2Col 的操作之后会得到一个输入矩阵,卷积的 Weights 也可以转换为一个矩阵,卷积的计算就可以转换为两个矩阵相乘的求解,得到最终的卷积计算结果。
推理引擎中的数据重排
首先归纳一下 Im2Col 算法计算卷积的过程。其具体过程如下(简单起见忽略 Padding 的情况,即认为 \(OH=IH,OW=IW\)):
将输入由 \(N×IH×IW×IC\) 根据卷积计算特性展开成 \((OH*OW)×(N*KH*KW*IC)\) 形状二维矩阵。显然,转换后使用的内存空间相比原始输入多约 \(KH∗KW−1\) 倍;
权重形状一般为 \(OC×KH×KW×IC\) 四维张量,可以将其直接作为形状为 \((OC)×(KH*KW*IC)\) 的二维矩阵处理;
对于准备好的两个二维矩阵,将 \((KH*KW*IC)\) 作为累加求和的维度,运行矩阵乘可以得到输出矩阵 \((OH*OW)×(OC)\);
将输出矩阵 \((OH*OW)×(OC)\) 在内存布局视角即为预期的输出张量 \(N×OH×OW×OC\),或者使用 Col2Im 算法变为下一个算子输入 \(N×OH×OW×OC\);
在权重数据的重排过程中,以上四个阶段在推理引擎中的执行方式和执行模块不一定在同一个阶段进行。其中 1,3,4 可能会在 Kernel 层执行,但 2 可能会在预编译阶段或者离线转换优化模块去执行。
而在 Input 数据的重排则会在正式计算时感知到数据流后进行。总的来说,不同的推理引擎在应用 Im2Col 算法时,输入数据的重排通常发生在以下阶段:
模型转换或图优化阶段:在这个阶段,推理引擎可能会分析模型的卷积层,并决定是否应用 Im2Col 算法。如果使用,引擎会相应地调整模型的结构,以便在执行卷积时进行数据重排。例如,TensorRT 在构建优化图时,会考虑是否将卷积层转换为 Im2Col 形式。
推理初始化阶段:在执行推理之前,推理引擎会进行初始化,这可能就包括为 Im2Col 操作分配必要的内存空间,并准备执行数据重排的代码路径。
预处理阶段:在实际执行推理之前,输入数据需要经过预处理,以满足模型的输入要求。这可能包括缩放、归一化和其他数据转换。在某些情况下,Im2Col 的重排也可以看作是预处理的一部分,虽然它与卷积操作更相关。
卷积层的前向传播阶段:在执行卷积层的前向传播时,如果使用了 Im2Col 算法,推理引擎会在这一阶段对输入数据进行重排。即在卷积操作之前,输入特征图会被转换为一个二维矩阵,其中每一行对应于卷积核在输入特征图上的一个位置。这个重排操作是 Im2Col 算法的核心部分。
后处理阶段:在卷积操作完成后,如果需要,推理引擎可能会将数据从 Im2Col 格式转换回原始格式。这通常是在卷积层的输出被进一步处理或传递到下一个网络层之前完成的。
在 AI 框架中,Im2Col 通常是为了优化卷积操作而设计的,它通过将多次卷积操作转换为一次大矩阵乘法,从而可以利用现有的高性能线性代数库来加速计算。随着 AI 框架的发展,很多框架也实现了更加高效的卷积算法,比如 Winograd 算法或者直接使用 cuDNN 等专门的卷积计算库,这些库内部可能对 Im2Col 操作进行了进一步的优化。
Im2Col 算法总结#
Im2Col 计算卷积使用 GEMM 库的代价是额外的内存开销。使用 Im2Col 将三维张量展开成二维矩阵时,原本可以复用的数据平坦地分布到矩阵中,将输入数据复制了 \(KH∗KW−1\) 份。
转化成矩阵后,可以在连续内存和缓存上操作,而且有很多库提供了高效的实现方法(BLAS、MKL),Numpy 内部基于 MKL 实现运算的加速。
在实际实现时,离线转换模块实现的时候可以预先对权重数据执行 Im2Col 操作,而 Input 数据的 Im2Col 和 GEMM 的数据重排会同时进行,以节省运行时间。
空间组合优化算法#
Im2Col 是一种比较朴素的卷积优化算法,在没有精心处理的情况下会带来较大的内存开销。空间组合(Spatial pack)是一种类似矩阵乘中重组内存的优化算法。它是指在应用 Im2Col 算法时,通过对卷积操作中的空间数据进行特定的组合和重排,以减少计算和内存访问的复杂性,从而提高推理效率。
空间组合优化算法是一种基于分治法(Divide and Conquer)的方法,基于空间特性,将卷积计算划分为若干份,分别处理。
具体优化方法#
常见的空间组合优化方法有:
分块卷积(Blocked Convolution):将大卷积核分解为多个小卷积核,每个小卷积核单独计算,这样可以减少内存访问和提高缓存利用率。这种方法在处理大型图像或特征图时特别有效。
重叠数据块(Overlapping Blocks):在进行 Im2Col 操作时,可以通过重叠数据块来减少边缘效应和填充(padding)的需求。这种方法可以减少计算量,但可能会增加内存访问的复杂性。
稀疏卷积(Sparse Convolution):对于稀疏数据,可以通过只对非零值进行卷积来减少计算量。这种方法在处理稀疏特征图时特别有效。
权重共享(Weight Sharing):在卷积操作中,同一个卷积核会在不同的位置重复使用。通过在 Im2Col 操作中利用这一点,可以减少权重数据的重复加载和存储。
张量化(Tensorization):利用特定硬件(如 GPU)的特定指令来优化张量操作,例如使用 SIMD(单指令多数据)指令集。这种方法可以加速 Im2Col 操作中的矩阵乘法。
循环展开和软件流水线:这些是编译器优化技术,可以用于优化循环结构,减少循环开销和提高指令级并行性。在 Im2Col 操作中,循环展开可以减少循环迭代的开销,而软件流水线可以优化数据流和处理流程。
内存复用:通过复用中间计算结果所占用的内存,可以减少总的内存使用。在 Im2Col 操作中,可以复用输入和输出数据的内存空间,以减少内存分配和释放的次数。
这些空间组合优化方法可以单独使用,也可以组合使用,以提高 Im2Col 操作的效率。在实际应用中,选择哪种优化策略取决于具体的模型结构、硬件平台和性能目标。随着 AI 框架和硬件的发展,许多框架已经采用了更加高效的卷积实现,如直接卷积(Direct Convolution)、Winograd 算法或利用专用硬件加速器,这些实现可能不再需要显式的 Im2Col 和 Col2Im 操作。
空间组合例子#
以分块卷积为例,如图所示在空间上将输出、输入划分为四份:
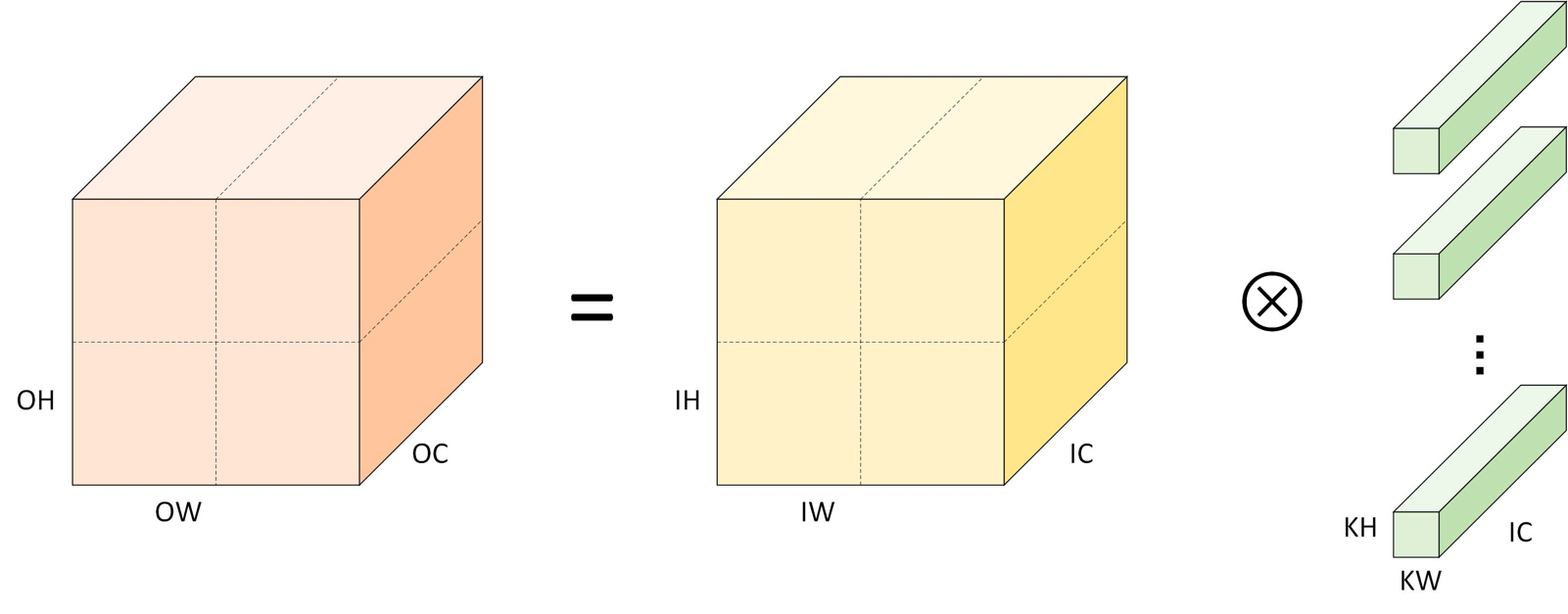
划分后,大卷积计算被拆分为若干个小卷积进行计算,小卷积块的大小必须与卷积核的大小相匹配。划分过程中计算总量不变,但计算小矩阵时访存局部性更好,可以借由计算机存储层次结构获得性能提升。
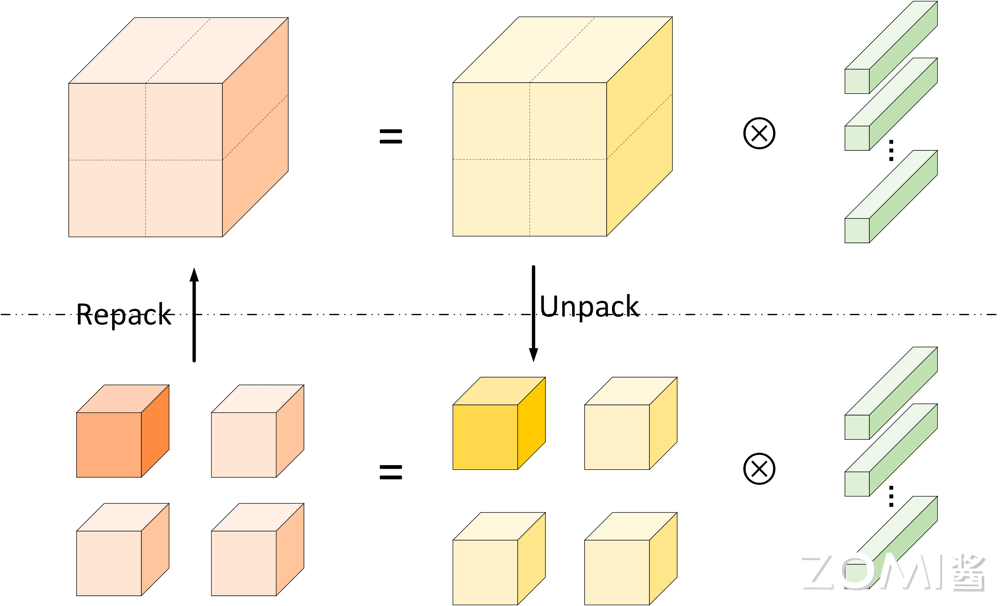
在传统的卷积操作中,输入特征和卷积核的每个通道都需要参与计算,这导致内存访问模式复杂,难以优化。而分组卷积将通道分成多个组,每个组内的通道数减少,使得内存访问更加规则和局部化,有利于提高缓存利用率。此外,这种基于分治法的分解策略,有助于提高并行处理的效率。在分组卷积中,每个组内的卷积核是独立的,这意味着不同组之间的权重和激活可以共享内存空间。这种共享可以减少内存占用,尤其是在使用大量卷积核的网络结构中。
算法注意与问题点#
空间组合优化注意点
值得注意的是,上文的描述中忽略了 Padding 的问题。实际将输入张量划分为若干个小张量时,除了将划分的小块中原始数据拷贝外,还需要将相邻的小张量的边界数据拷贝:
这里的 \(2(KH−1)\) 和 \( 2(KW−1)\) 遵循 Padding 规则。规则为 VALID 时,可以忽略;规则为 SAME 时,位于 Input Tensor 边界一边 Padding 补 0,不在 Input Tensor 边界 Padding 使用邻居张量值。也就是说,在真正使用这种方法的时候,可以通过重叠数据块来减少边缘效应和填充(padding)的需求。这种方法可以减少计算量,但可能会增加内存访问的复杂性。
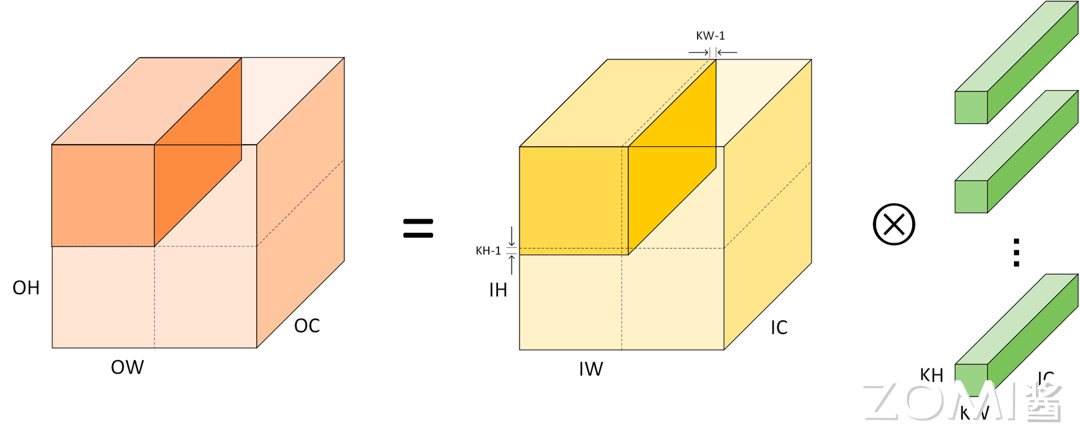
空间组合优化问题点
实际应用中可以拆为很多份。例如可以拆成小张量边长为 4 或者 8 ,从而方便编译器向量化计算操作。随着拆分出的张量越小,Padding 引起的额外内存消耗越大,其局部性也越高,负面作用是消耗的额外内存也越多。
对于不同规模的卷积,寻找合适的划分方法不是一件容易的事情。正如计算机领域的许多问题一样,该问题也是可以自动化的,例如通过使用 AI 编译器 可以在这种情况下寻找较优的划分方法。
小结与思考#
m2Col 优化原理通过将卷积操作转换为矩阵乘法,减少内存访问次数,提高计算效率。Caffe 等早期 AI 框架利用此方法优化卷积计算。
Im2Col 将输入数据重排为连续的二维矩阵,然后通过矩阵乘法(GEMM)实现卷积计算,适用于各种卷积参数,与 Matmul 性能相当。
空间组合优化算法通过特定的数据组合和重排,减少计算和内存访问复杂性,提高推理效率。