计算图的调度与执行#
在前面的内容介绍过,深度学习的训练过程主要分为以下三个部分:1)前向计算、2)计算损失、3)更新权重参数。在训练神经网络时,前向传播和反向传播相互依赖。对于前向传播,沿着依赖的方向遍历计算图并计算其路径上的所有变量。然后将这些用于反向传播,其中计算顺序与计算图的相反。
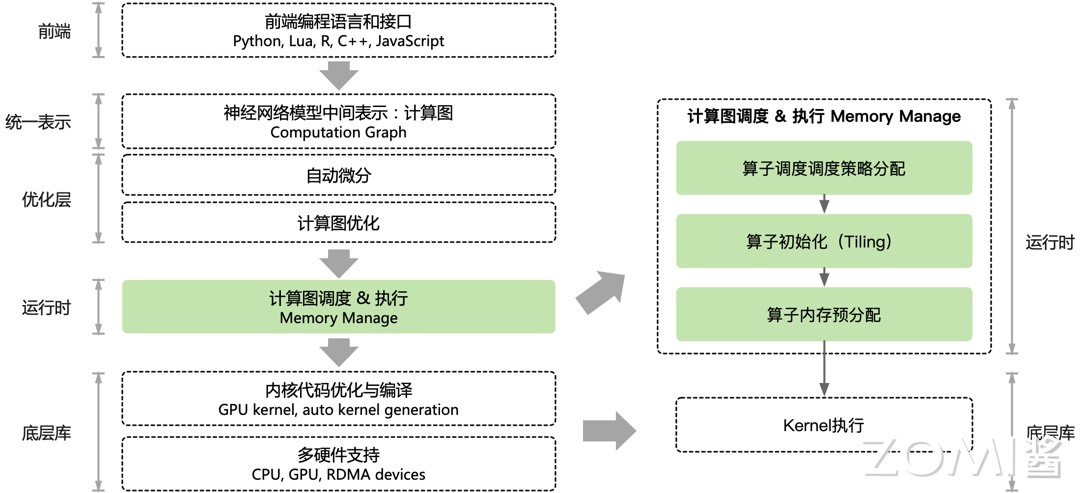
基于计算图的 AI 框架中,训练的过程阶段中,会统一表示为由基础算子构成的计算图,算子属于计算图中的一个节点,由具体的后端硬件进行高效执行。
目前 AI 框架的前端负责给开发者提供对应的 API,通过统一表示把开发者编写的 Python 代码表示为前向计算图,AI 框架会根据前向计算图图,自动补全反向计算图,生成出完整的计算图。神经网络模型的整体训练流程,则对应了计算图的数据流动的执行过程。算子的调度根据计算图描述的数据依赖关系,确定算子的执行顺序,由运行时系统调度计算图中的节点到设备上执行。
实际上,计算图的执行方式,可以分为两种模式:1)逐算子下发执行的交互式方式,如 PyTroch 框架;2)以及整个计算图或者部分子图一次性下发到硬件进行执行,如 TensorFlow 和 MindSpore。无论采用哪种模式,其大致架构如下所示。
图调度#
计算图的调度主要是指静态图。在静态图中,需要先定义好整个计算流,再次运行的时就不需要重新构建计算图,因此其性能更加高效。之所以性能会更高效,是因为会对计算图中的算子的执行序列进行调度优化。
什么是算子#
AI 框架中对张量计算的种类有很多,比如加法、乘法、矩阵相乘、矩阵转置等,这些计算被称为算子(Operator),它们是 AI 框架的核心组件。为了更加方便的描述计算图中的算子,现在来对算子这一概念进行定义:
狭义的算子(Kernel):对张量 Tensor 执行的基本操作集合,包括四则运算,数学函数,甚至是对张量元数据的修改,如维度压缩(Squeeze),维度修改(reshape)等。
广义的算子(Function):AI 框架中对算子模块的具体实现,涉及到调度模块,Kernel 模块,求导模块以及代码自动生成模块。
我们在后续的内容中会将狭义的算子,统一称之为核(Kernel),在 AI 框架中,使用 C++ 实现层里的算子指的就是这里的 Kernel,而这里的 Kernel 实现并不支持自动梯度计算(Autograd)模块,也不感知微分的概念。
广义的算子我们将其称之为函数或方法(Function),这也是平时经常接触到的 AI 框架中 PyTorch API,包括 Python API 和 C++ API,其配合 PyTorch Autograd 模块后就可以支持自动梯度求导计算。
算子间调度#
无论是大模型还是传统的神经网络模型,实际上最后执行都会落在单台设备环境上执行对应的算子。对单设备执行环境,制约计算图中节点调度执行的关键因素是节点之间的数据流依赖和具体的算子。
假设继续以简单的复合函数为例子:
下图是函数对应的计算图,一共有 5 个算子:
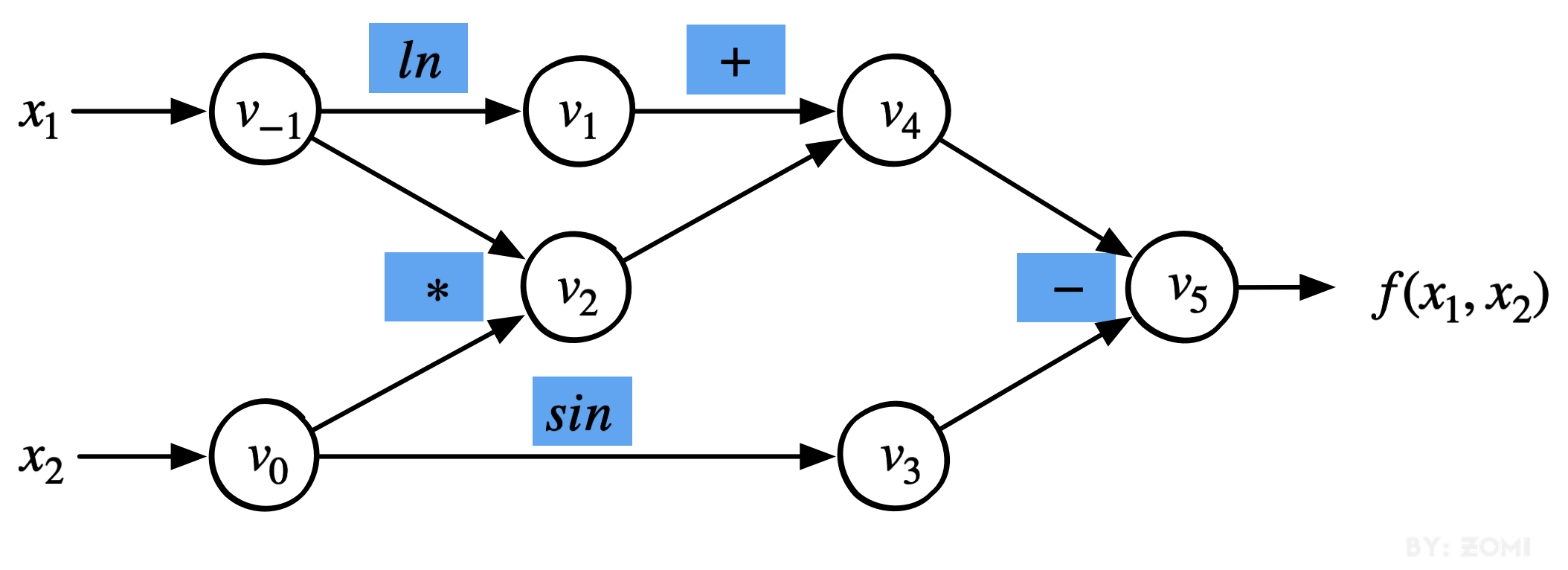
AI 框架根据上述计算图的数据流的依赖关系,在单设备环境下,依次调用具体的算子可以如下所示:
# 正向执行算子
Log(v_(-1), 2) -> v1
Mul(v_(-1), v0) -> v2
Sin(v0) -> v3
Add(v1, v2) -> v4
Sub(v4, v3) -> v5
# 反向执行算子
Sub_grad(v5, v5_delta) -> v4_delta
...
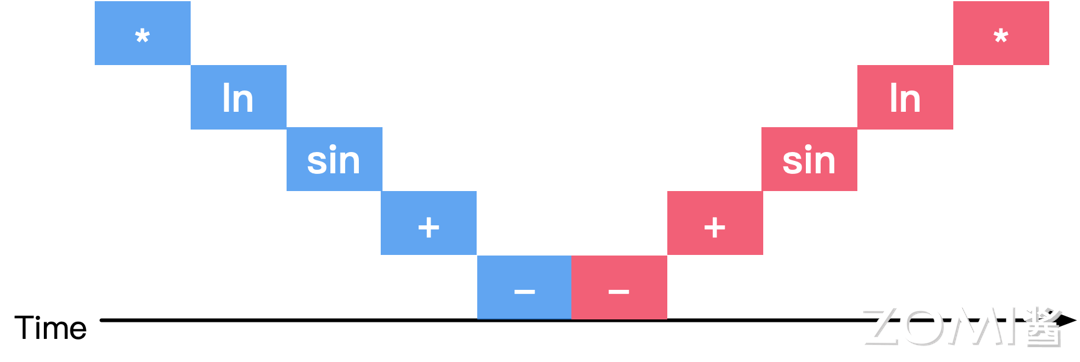
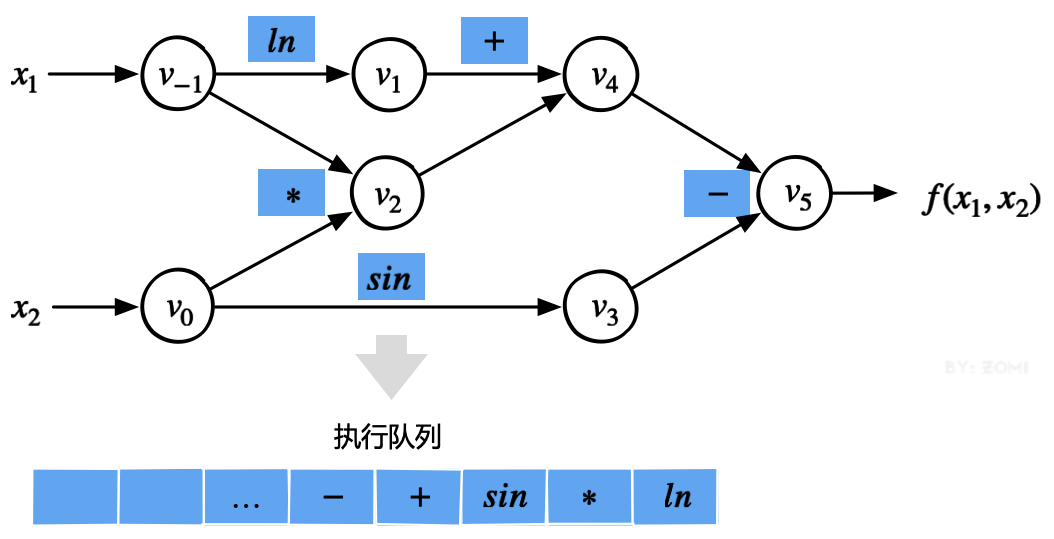
由于计算图准确的描述了算子之间的依赖关系,运行时的调度策略可以变得十分直接。根据计算图中的数据流依赖关系和计算节点函数,通过先进先出队列来执行具体的计算逻辑:
初始状态下,AI 框架会在运行时将计算图中入度为 0 的节点加入到 FIFO(First-In-First-Out)队列中
从 FIFO 队列中选择下一个节点,分配给线程池中的一个线程执行计算;
当前节点执行结束后,会将其后继节点加入就绪队列,当前节点出队;
AI 框架在运行时继续处理 FIFO 队列中的剩余节点,直到遍历完所有的节点,队列为空。
图中按照数据流约束执行对应的计算图的一个可能调度序列。其中蓝色为正向计算时候用到的算子,红色为反向计算时候用到的算子。这种调度方式主要以 PyTorch 的默认执行方式,TensorFlow 的 eager 模式,以及 MindSpore 的 PyNative 模式为主。
算子并发调度#
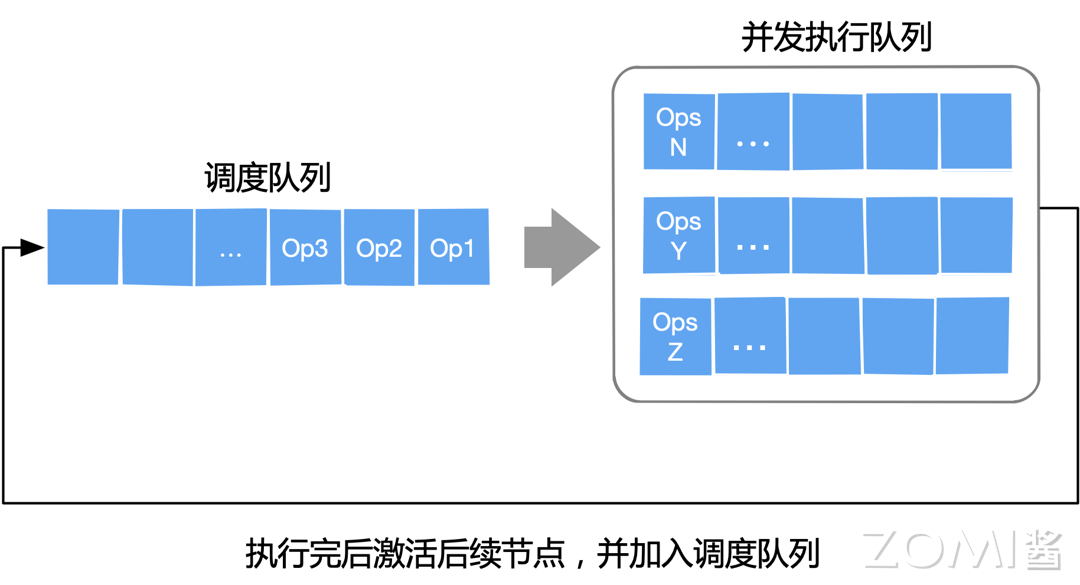
单设备算子间使用单线程管理先进先出队列进行调度,这种方式是直接也是最原始的。实际 AI 框架会根据计算图,找到相互独立的算子进行并发调度,提高计算的并行性。
这个时候,就非常依赖于计算图能够准确的描述了算子之间的依赖关系,通过后端编译优化功能或者后端编译优化的 Pass,提供并发执行队列的调度操作。
以 TensorFlow 和 MindSpore 这一类默认使用静态图的 AI 框架为例。其默认算子执行调度策略中,计算图中的节点会被分类为低代价节点(一般是仅在 CPU 上执行的一些拼接节点)和高代价节点(张量计算节点)。
先进先出队列中的一个节点被分配给线程池中的线程调度执行时,这个线程会一次执行完计算图中所有低代价节点;部分 AI 框架会执行预编译阶段,在计算图调度模块中预先遍历计算图,区分高代价节点和低代价加点,并对其优先级根据具体情况进行按等级划分。假设遇到高代价节点时,将该节点派发给线程池中其他线程执行,从而实现算子并发调度执行。
算子异构调度#
在手机端侧异构计算环境中,主要存在 CPU、GPU 以及 NPU 等多种异构的计算 IP,因此一张计算图可以由运行在不同计算 IP 的算子组成为异构计算图,继续以
:eqref:autodiff_04_eq1为例,下图展示了一个在端侧 SoC 中典型的由异构 IP 共同参与的计算图。
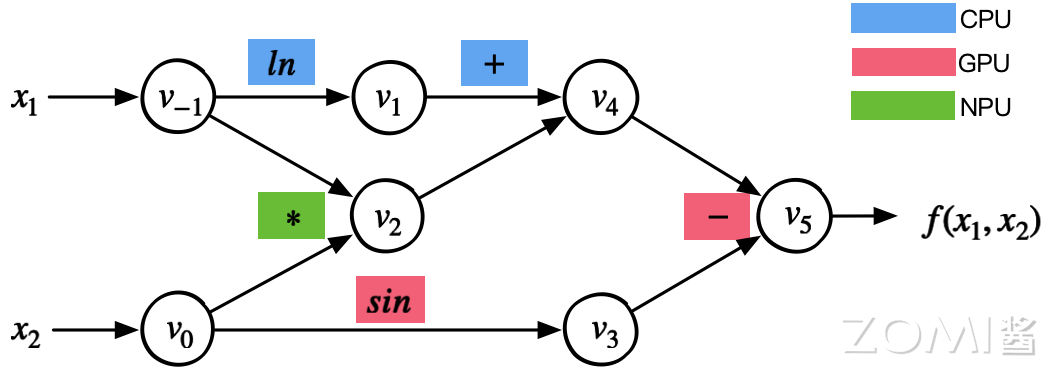
假设该手机 SoC 芯片有 CPU、GPU 和 NPU 三款计算 IP,所述计算图由如下几类异构计算 IP 对应的算子组成:
CPU 算子:通过 CPU 执行的算子,CPU 计算的性能取决于是否能够充分利用 CPU 多核心的计算能力。
GPU 算子:由 GPU 执行算子的计算逻辑,由于 GPU 具备并行执行能力,可以为高度并行的 Kernel 提供强大的并行加速能力。
NPU 算子:由专门为高维张量提供独立 Kernel 计算的执行单元,NPU 优势是支持神经网络模型特殊的算子,或者子图执行。
计算图能够被正确表达的首要条件是准确标识算子执行所在的不同设备,例如图中,使用不同的颜色,标识 CPU、GPU 和 NPU Kernel,同一时间可以在不同的计算 IP 上执行不同的计算。目前主流 AI 框架均提供了指定算子所在运行设备的能力。
异构计算图的优点在::1)异构硬件加速,将特定的计算放置到合适的硬件上执行;2)算子间的并发执行,从计算图上可知,没有依赖关系的算子或者子图,逻辑上可以被 AI 框架并发调用。
不过在实际工程经验过程来看,目前采用算子异构调度的方式作为推理引擎的新增特性比较多,主要原因在于:1)调度逻辑复杂,程序控制实现起来并不简单,即使自动化方式只能针对部分神经网络模型;2)大部分神经网络模型的结构,仍然以高度串行为主,上下节点之间的依赖较重;3)异构调度涉及到不同 IP 计算结果之间的通信,通信的开销往往大于计算的开销。导致计算需要等待数据的同步与传输。
图执行#
AI 框架生成计算图后,经过图调度模块对进行图进行标记,计算图已经准备好被实际的硬件执行,根据硬件能力的差异,可以将异构计算图的执行分为三种模式:1)单算子执行、2)整图下沉执行与 3)图切分到多设备执行。
第一种单算子执行主要针对 CPU 和 GPU 的场景,计算图中的算子按照输入和输出的依赖关系被逐个调度与执行。整图下沉执行模式主要是针对 DSA 架构的 AI 芯片而言,其主要的优势是能够将整个计算图一次性下发到设备上,无需借助 CPU 的调度能力而独立完成计算图中所有算子的调度与执行,减少了主机和 AI 芯片的交互次数,借助 AI 芯片并行加速能力,提高计算效率和性能。
图切分与多设备执行的方式是面向大规模计算场景的,如现在很火的大模型。由于计算图自身表达的灵活性,对于复杂场景的计算图在 AI 芯片上进行整图下沉执行的效率不一定能达到最优,或者在单个 AI 芯片上不能完整放下一张计算图。因此可以将计算图进行拆分,把大模型产生的计算图分别放在不同的 AI 加速芯片上面。此外,对于 AI 芯片执行效率低下的部分分离出来,交给 CPU 处理,将更适合 AI 芯片的子图下沉到 AI 芯片进行计算,这样可以兼顾性能和灵活性两方面。
单算子执行#
单算子执行类似于串行执行,将计算图展开为具体的执行序列,按照执行序逐个 Kernel 执行,如图所示。其特点为执行顺序固定,单线程执行,对系统资源要求相对较低。
单算子执行的一般执行过程:算子在高级语言如 Python 侧被触发执行后,经过 AI 框架初始化,其中需要确定算子的输入输出数据、算子类型、算子大小以及对应的硬件设备等信息,接着 AI 框架会为该算子预分配计算所需的内存信息,最后交给具体的硬件加速芯片执行具体的计算。
单算子的执行方式好处在于其灵活性高,算子直接通过 Python 运行时调度:
通过高级语言代码表达复杂的计算逻辑,尤其是在需要控制流以及需要高级语言的原生数据结构来实现复杂算法的场景;
便于于程序进行调试,开发者可以在代码解释执行过程中控制需要需要调试的变量信息;
利用高级语言的特性,如在复杂计算加速任务中与 Python 庞大而丰富的生态库协同完成。
图下沉执行#
单算子调度具有着较高的易用性等优点,其缺点也很明显:
难于对计算图进行极致的性能优化,缺乏计算图的全局信息,单算子执行时无法根据上下文完成算子融合,代数化简等编译优化的工作;
缺乏计算图的拓扑关系,计算图在具体执行时退化成算子执行序列,只能按照给定的队列串行调度执行,即无法在运行时完成并行计算。
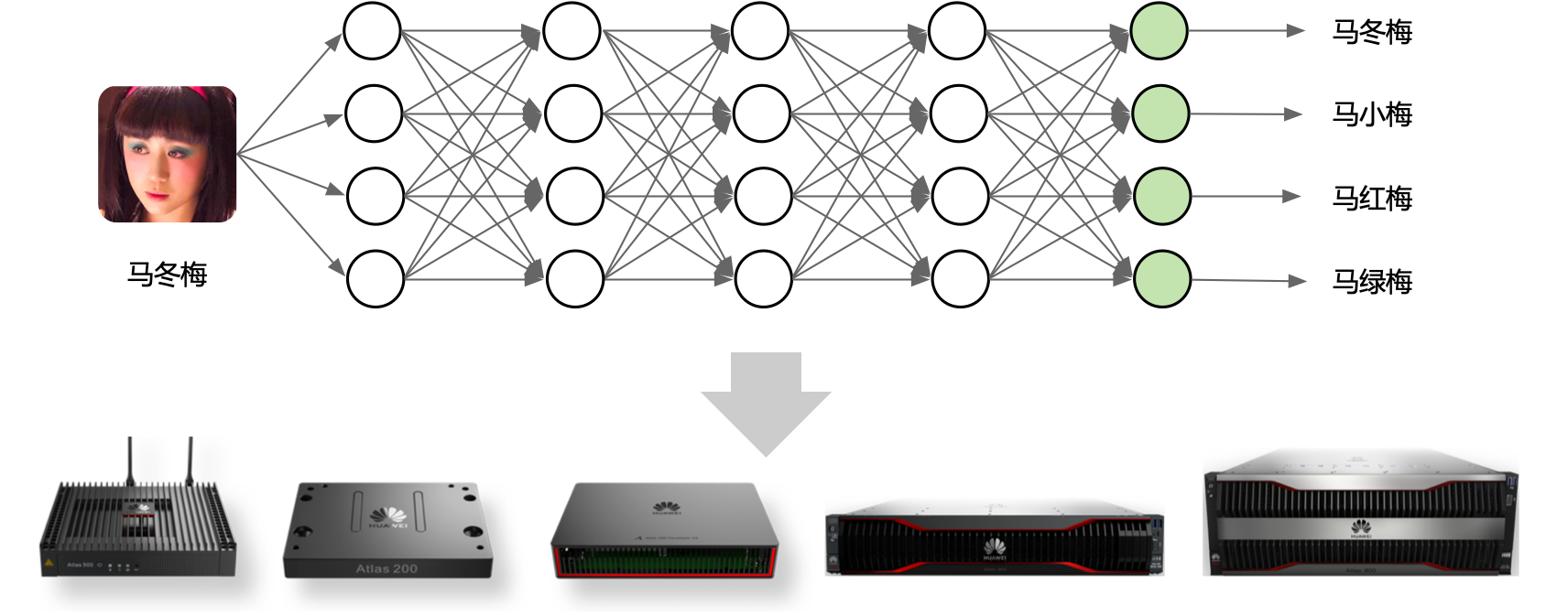
整图下沉式的执行方式,是通过专用的 AI 加速芯片,将整个计算图或者部分计算图(子图)一次性下发到 DSA 芯片上以完成计算图的计算。如谷歌 TPU 和华为昇腾 NPU,多个算子可以组成一个子图,子图在执行之前被编程成一个具体的任务,将包含多个算子的任务一次性下发到硬件上直接执行。
计算图下沉的执行方式避免了在计算过程中,host 主机侧和 device 设备侧频繁地进行交互,CPU 下发一个算子到 NPU,再从队列中取出下一个节点下发到 NPU,因此可以获得更好的整体计算性能。然而计算图下沉执行的方式也存在一些局限,例如算子在动态 Shape,复杂控制流、副作用等场景下会面临较大的技术挑战。
图切分与多设备执行#
对于上面两个简单的神经网络模型,在数据流依赖的约束下只存在串行调度方案,牵强地用并发和异构调度作为例子。但是在实际的网络模型中,对一些复杂的神经网络模型存在多分枝,特别是 CV 在检测领域。
目前大模型非常的火,典型代表如下图 Transformer Decoder 堆叠的模型结构,这时如果后端有多个执行算子 Kernel 的硬件加速设备,因为模型结构太大,参数量太多,没有办法在一张 AI 加速卡上放下整个计算图,因此在 AI 框架的运行时在调度执行计算图前,可以对网络模型进行切分,按照模型结构层数进行切分,把 2/3 层 Transformer 结构模块放在同一设备上。
下面以简单的模型并行对神经网络模型的计算图进行切分,对模型按层数来切分,也可以按照模型单一层横向来切分出不同的子图。
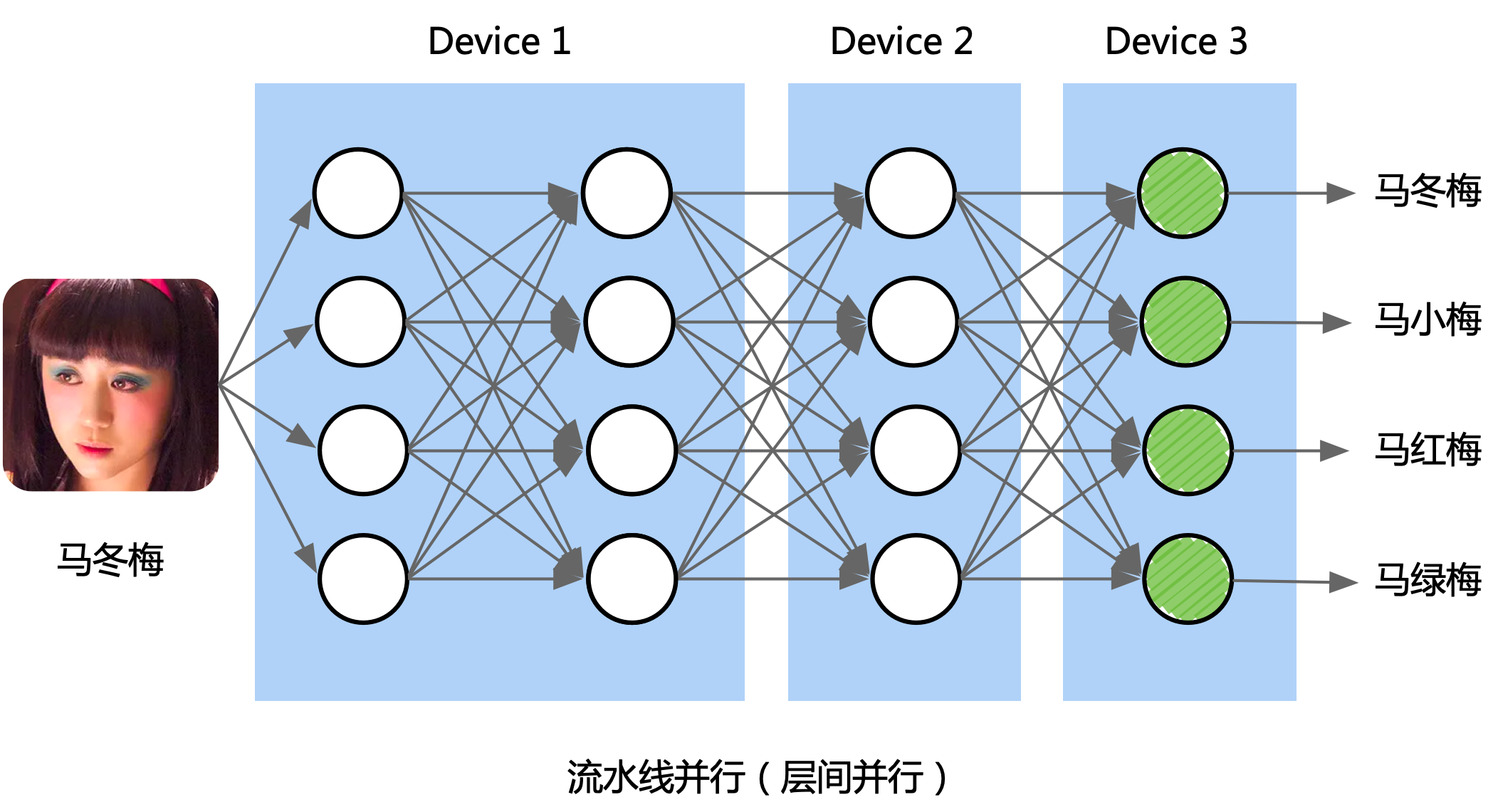
多计算设备环境下执行计算图,AI 框架的运行时需要解决,如何将计算图中的具体计算,放置到不同设备上以及如何管理跨设备数据传输两个问题:
计算图切分:给定一个计算图,并将计算图切分为不同的子图或者单算子后,放置到多个计算设备上,每个设备拥有计算图的一部分。
跨设备通信:子图被放置不同设备上,此时 AI 框架会为计算图新增一些跨设备的链接和通信节点(All Reduce 或 All Gather 等集合通信),实现跨设备数据传输。
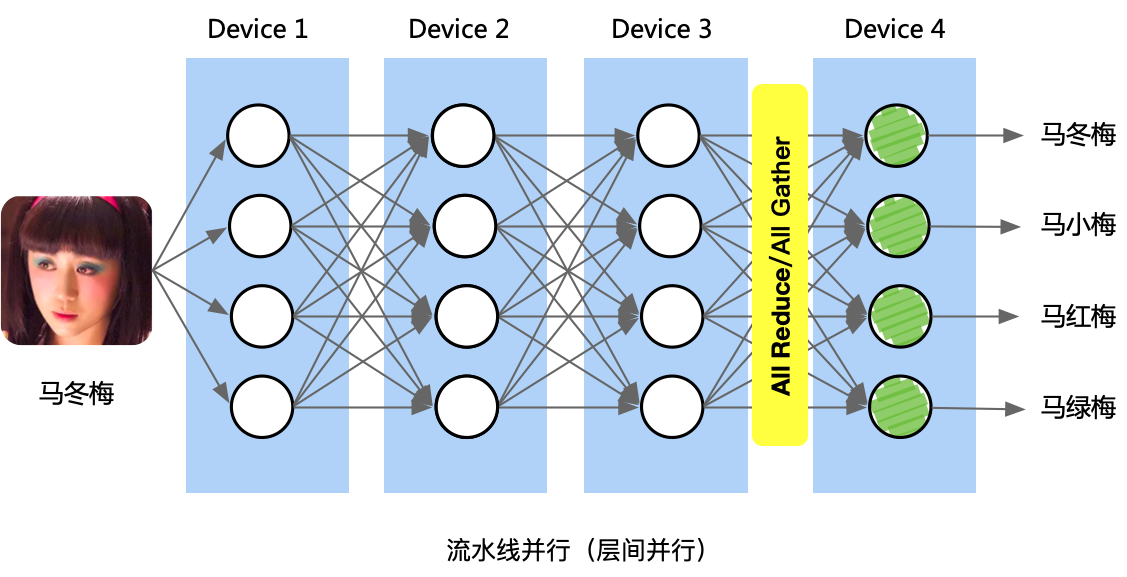
实际上做好计算图切分,并把计算图映射到多设备是一个复杂的组合优化问题,目前针对大模型在千卡集群规模下同时进行训练的最优并行策略寻优,称为自动并行。
自动并行需要在代价模型(Cost Model)的辅助下,预估在集群环境下,跨设备通信消耗的时间以及每个算子在设备上的运行时间如何随着输入输出张量大小的改变而变化,最终以数据流依赖为约束,均衡并行执行和数据通信这一对相互竞争的因素,实现集群训练效率利用率最大化。
PyTorch 算子执行#
PyTorch 的函数是一个非常复杂核心的模块,其大部分代码都是由 PyTorch tool 根据模板文件自动生成。如果想要查看其源代码,无法直接在 PyTorch 的 GitHub 代码库中搜索到,必须要将代码下载到本地并进行编译。当调用函数时,就会接触到 PyTorch 的调度模块。
以 PyTorch 的加法为例,假设调用 torch.add 函数 API 时,AI 框架总共会经历两次调度:
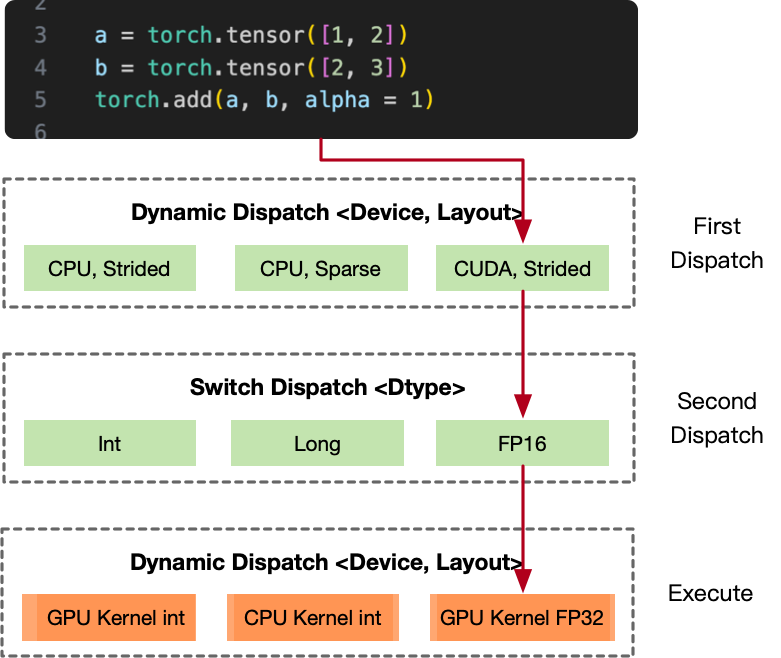
第一次调度会根据执行张量的设备(device)和布局(layout)动态选择对应的实现函数,比如 <CPU, Strided> Tensor,<CPU, Sparse> Tensor或者<GPU, , Strided> Tensor。不同设备布局的实现,可能会编译在不同的动态链接库里。
第二次调度则会根据张量元素的数据类型,通过 switch 分支的方式进行一次轻量级的静态选择,最终选出合适的 Kernel 来执行对张量的操作。
Kernel 主要是算子的计算模块,但是别忘记了在深度学习中,算子还包含求导模块。计算模块主要定义了 Kernel 的计算步骤,需要先在 aten/src/ATen/native/native_functions.yaml 中声明 Kernel 计算模块的函数签名,然后在 native/ 目录下实现该函数。
在前面的函数调用中,主要就通过 Kernel 对张量进行操作。求导模块主要是对计算模块的一个反向求导,需要直接在 tools/autograd/derivatives.yaml 中声明定义求导的过程,剩下就可以交给 Autograd 代码生成模块自动生成对应的代码。
小结与思考#
计算图的调度与执行是 AI 框架中的关键环节,涉及如何高效地管理和分配计算资源,以优化训练和推理过程。
调度主要分为图调度和算子间调度,包括静态图中的优化执行和单设备或异构计算环境中的并发及异构调度,以提高计算效率和资源利用率。
图执行方式包括单算子执行、整图下沉执行和图切分到多设备的并行执行,以适应不同的硬件架构和计算规模需求。
PyTorch 中的算子执行涉及两次调度,首先是选择具体实现函数,然后是选择具体的 Kernel 执行操作,整个过程由 Autograd 模块支持自动求导。