基本介绍#
在 AI 框架发展的最近一个阶段,技术上主要以计算图来描述神经网络。前期实践最终催生出了工业级 AI:TensorFlow 和 PyTorch,这一时期同时伴随着如 Chainer、DyNet、CNTK、PaddlePaddle、JAX 等激发了框架设计灵感的诸多实验课程。
TensorFlow 和 PyTorch,特别是 PyTorch 代表了今天 AI 框架两种不同的设计路径:系统性能优先改善灵活性和灵活性易用性优先改善系统性能。这两种选择,随着神经网络算法研究和应用的更进一步发展,使得 AI 框架在技术实现方案的巨大差异。
随着神经网络模型越来越复杂,包括混合专家模型 MOE、生成对抗网络 GAN、注意力模型 Attention Transformer 等。复杂的模型结构需要 AI 框架能够对模型算子的执行依赖关系、梯度计算以及训练参数进行快速高效的分析,便于优化模型结构、制定调度执行策略以及实现自动化梯度计算,从而提高 AI 框架训练的效率。
综上所述,目前主流的 AI 框架都选择使用计算图来抽象神经网络计算表达,通过通用的数据结构(张量)来理解、表达和执行神经网络模型,通过计算图可以把 AI 系统化的问题形象地表示出来。
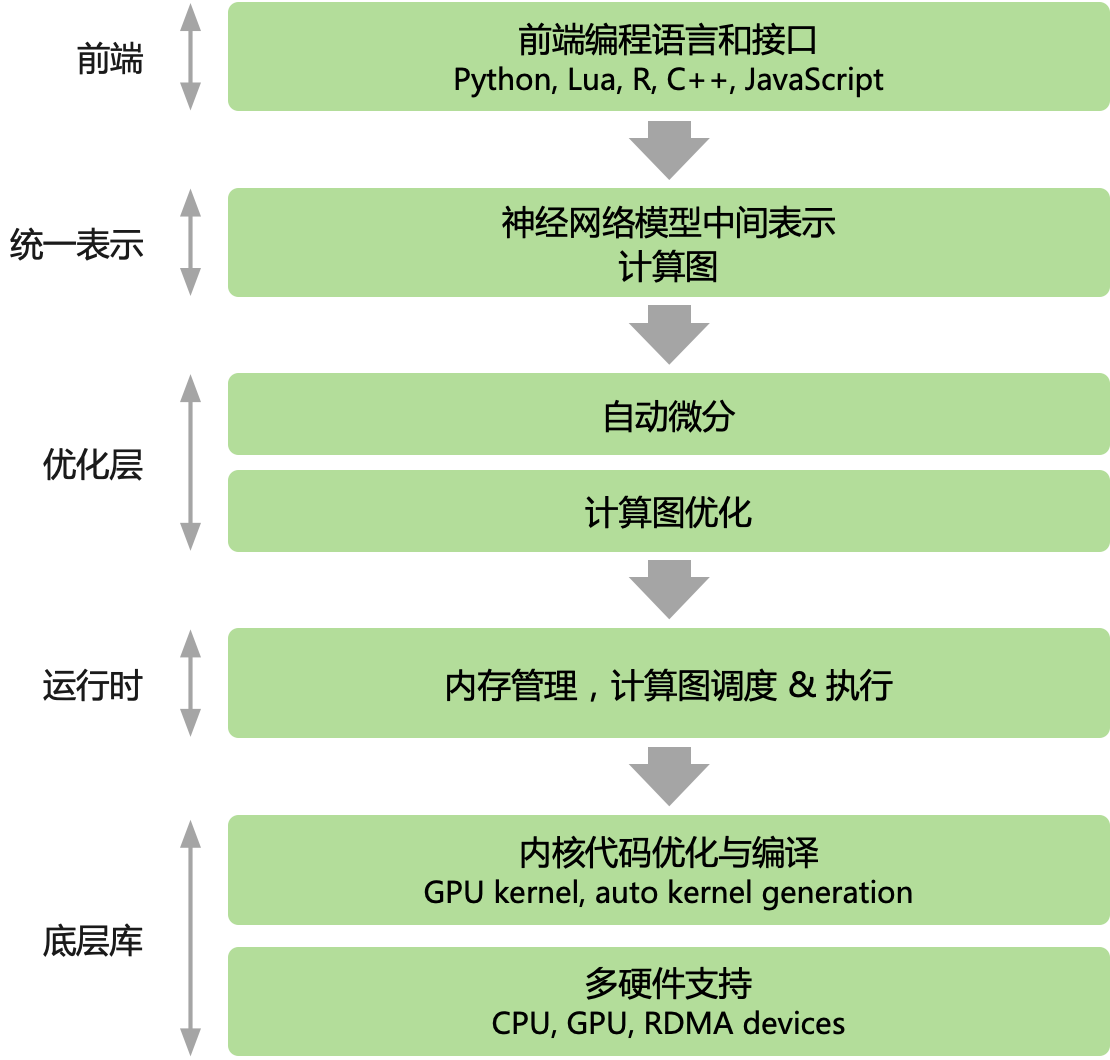
有了对计算图的基本了解之后,就开始深入地了解计算图,跟自动微分之间的关系。即计算图、神经网络在真正执行计算,反向传播如何传播,如何表达自动微分的概念,而不是停留在抽象的数学含义。
神经网络的训练流程主要包括一下五个过程:1)前向计算、2)计算损失、3)自动求导、4)反向传播、5)更新模型参数。在基于计算图的 AI 框架中,这五个阶段统一表示为由基本算子构成的计算图,算子是数据流图中的一个节点,由后端进行高效实现。
但是在程序实现过程中,会遇到很多编程性问题,例如控制流(if、else、while、for 等)跟程序相关,而非跟计算和数学表示相关的内容。因此会展开计算图和控制流之间的关系,也深入地去探讨计算关于调度和具体的执行方式,从而更好地、灵活地表达计算图。