图算 IR#
本节将围绕计算图介绍相关内容。首先介绍计算图的基本构成,包括计算图的整体介绍、与自动微分的关系、控制流的表示方法等;接着将介绍 AI 框架产生计算图的方式,包括产生静态图和产生动态图的方式;之后将介绍静态和动态计算图的内容,包括 AI 框架关于计算图的不同方案,例如现在大部分的 AI 框架都是从动态的计算图转到静态的计算图,而 MindSpore 是一开始支持静态的计算图,最后支持动静统一的动静态计算图;最后介绍计算图对 AI 编译器有何作用。
计算图基本构成#
目前主流的 AI 框架,在后端会将前端编程语言(例如 Python)构建的网络模型前向与反向的梯度计算以计算图的形式来表示。
计算图是一个有向无环图(Directed Acyclic Graph,DAG),主要用来表示神经网络模型在训练与推理过程中的计算逻辑与状态,它由基本数据结构张量(Tensor) 和基本运算单元算子(Operator) 构成。
在计算图中,常用节点来表示算子,节点间的有向线段来表示张量状态,同时也描述了计算间的依赖关系。
基于计算图 AI 框架#
目前基于计算图的 AI 框架主要由基本的数据结构 Tensor 张量和基本的运算单元 Operator 算子组成。
在数学中,张量是标量和向量的推广,而在机器学习领域中,一般将多维数据称为张量。AI 框架的 Tensor 张量具有 Tensor 形状和元素类型等基本属性,常见的二维张量和三维张量的示意图分别如下所示:
AI 框架的 Operator 算子一般由最基本的代数算子组成,可以根据神经网络模型的需求组成复杂的算子,常见的 Operator 算子如下表所示。

算子一般具有 N 个输入的 Tensor 张量,M 个输出的 Tensor 张量,其中 N 和 M 均为正整数。此外,“算子”是 AI 框架的一个概念,而在硬件底层或者使用 CUDA 编写部分算子表达时,一般称为 CUDA Kernel。
基于数据流图 AI 框架#
在上文中提到,计算图是一个有向无环图(DAG),在图中使用节点表示 Operator 算子,使用边代表 Tensor。
通过使用该表示方法,正向传播的计算图如下图中左图所示,结合了正向传播和反向传播的计算图如下图右图所示。此外,在计算图中也可能存在特殊的操作,例如 For、While 等构建控制流,也可能存在特殊的边,例如使用控制边表示节点间依赖。
AI 框架如何生成计算图#
本节将介绍在开发者编写代码后 AI 框架生成计算图相关的内容,包括计算图与自动微分的关系、AI 框架生成静态计算图的方式、生成动态计算图的方式等。
计算图和自动微分#
上文中提到计算图是一个有向无环图(DAG),包括正向传播的计算图和反向传播的计算图两部分内容。但是,在开发者基于 AI 框架提供的 API 构建神经网络模型时,一般只需编写神经网络正向传播的计算图,而无需编写反向传播的计算图。
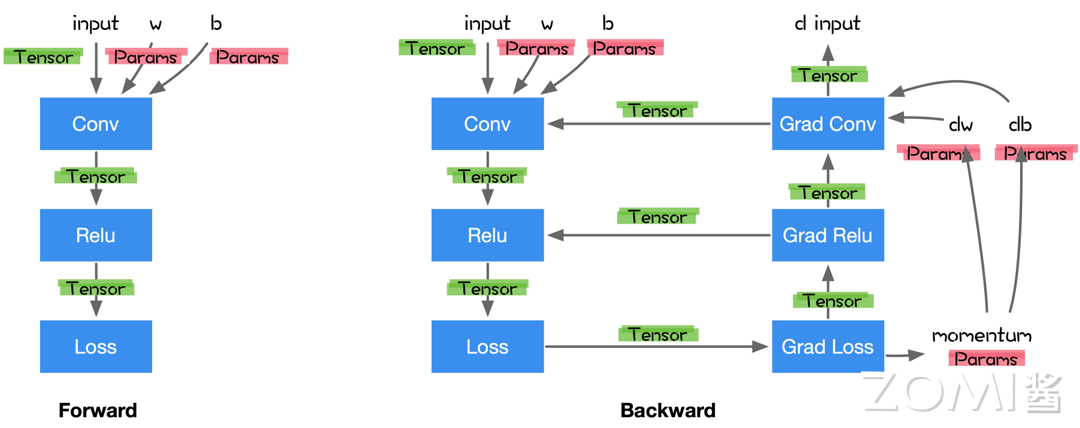
这是因为主流的 AI 框架将会自动分析神经网络的代码,不仅建立正向传播的计算图,也建立反向传播的计算图,如下图所示,实线部分为正向传播的计算图,虚线部分为 AI 框架自动建立的反向传播计算图。
在将正向图与反向图结合生成完整的计算图后,AI 编译器将可以对计算图进行后续处理,包括但不限于算子融合、常量折叠等多种优化 Pass。
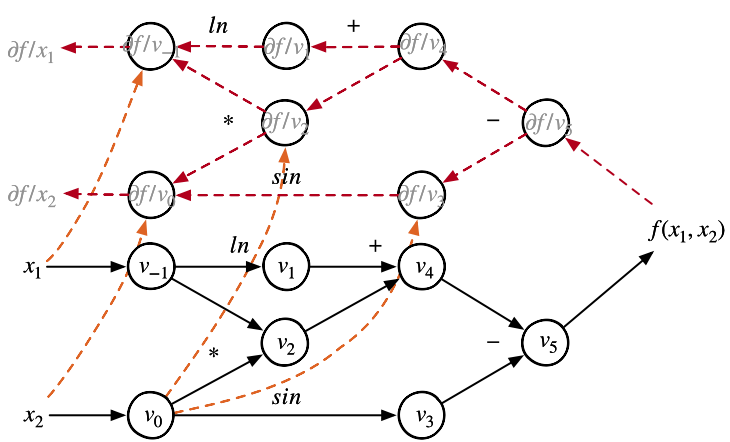
AI 框架将会自动分析上图中表示的计算图的计算过程,通过追踪计算图中的数据流,对其中的每个参数都进行精确地微分,获取相应的梯度,以便后续计算中使用这些梯度在神经网络的训练过程中进行参数更新,上文所示的计算图的自动微分示意图如下图所示。
现代的 AI 框架,如 PyTorch、MindSpore 和 PaddlePaddle,都具备自动微分的功能,极大的简化了神经网络模型的开发和训练过程。

AI 框架生成静态图#
在 AI 框架生成静态图的模式下,当开发者使用前端语言(例如 Python)定义模型形成完整的程序后,神经网络模型的训练不使用前端语言的解释器执行计算任务,而是由 AI 框架分析前端语言描述的完整模型,获取网络层之间的连接拓扑关系和参数变量设置、损失函数等信息,并使用静态数据结构重新描述神经网络的拓扑结构和其他模型组件。
如下代码为使用 MindSpore 开发的一部分代码,AI 框架将对这些代码进行 API 分析和重构,进行源码的转换,变成静态的计算图。
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512)
nn.ReLU()
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
AI 框架生成动态图#
在 AI 框架生成动态图的模式下,开发者使用前端语言(例如 Python)进行开发模型,并采用前端语言自身的解释器对代码进行解释执行,利用 AI 框架自身提供的算子分发功能,算子将会在调用时即刻执行并输出结果。
动态图模式采用用户友好的命令式编程范式,具有灵活的执行计算特性,可以使用前端语言的原生控制流,使神经网络模型的开发构建过程更加简洁,充分发挥前端语言的编程友好特性。但由于在执行前无法获取完整的网络结构,因此不能使用静态图适用的图优化技术提高计算执行性能。
静态和动态计算图#
动态图和静态图比较#
特性 |
静态图 |
动态图 |
|---|---|---|
即时获取中间结果 |
否 |
是 |
代码调试难易 |
难 |
简单 |
控制流实现方式 |
特定语法 |
前端语言语法 |
性能 |
优化策略多、性能更加 |
图优化受限、性能较差 |
内存占用 |
相对较少 |
相对较多 |
部署能力 |
可直接部署 |
不可直接部署 |
上表从代码即时获取中间结果、代码调试难度、内存占用等方面对比了动态图与静态图的特点。一般静态图的模型权重文件不仅包含权重数据,还包含了计算图的信息,而动态图一般用于训练阶段,在训练完成后通常不会保存计算图的信息。
通常在推理阶段会使用模型的计算图的信息,因此在部署能力方面,静态图优于动态图。并且,静态图可以进行一些编译时优化,这也是 PyTorch 2.0 引入的 Dynamo 这一重要特性的作用之一,能够将 PyTorch 的的动态图转换为静态图,以提升性能。
动态图转换为静态图#
目前,动态图转换为静态图主要有两种方式,分别为基于追踪转换的方式和基于源码转换的方式。基于追踪转换的方式以动态图的模式执行并记录调度的算子,保存神经网络模型的计算图的信息,构建和保存为静态图模型。
例如 PyTorch 的 FX,基于源码转换的方式将分析前端的代码,将动态图代码自动转换为静态图代码,在 AI 框架的后端使用静态图的方式执行程序,例如 PyTorch 的 JIT 等。
计算图对 AI 编译器作用#
方便底层编译优化#
在前端获取计算图最主要的作用是便于底层进行编译优化。
计算图可以描述神经网络训练的全过程,允许 AI 框架在执行之前获取神经网络模型的全局信息,从而执行部分依赖全局信息的系统级优化,使 AI 编译器可以对计算过程的数据依赖情况进行分析,可以作为 AI 框架中的高层中间表示,像 LLVM 一样通过若干图优化 Pass 来简化计算图或提高执行效率,从而简化数据流图,进行动态和静态的内存优化,也可以调整算子间的调度策略,改善运行时 Runtime 性能等。
例如,在 MindSpore 中利用反向微分计算梯度通常实现为数据流图上的一个优化 Pass,其余优化 Pass 将在后续章节详细介绍。
计算图也可以序列化保存而无需再次编译前端源代码,从而进行推理或训练过程的加速,也可以将神经网络模型的中间表示转换为不同的硬件代码或直接部署在硬件上,提供高效的推理服务。
分层优化便于扩展#
计算图也便于 AI 编译器进行分层优化和拓展。从优化的角度,将 AI 编译器的前端优化部分切分为三个解耦的优化层,分别为计算图优化、运行时调度优化、算子/内核执行优化。
不同层面具有不同的优化 Pass,对 AI 系统整体的优化具有重要的意义。从拓展的角度,在构建新的网络模型结构、执行新的训练算法时,可以向计算图层添加新的算子、针对不同硬件内核实现计算优化、注册算子和内核函数并在运行时派发硬件执行等,为 AI 系统提供了灵活易用的拓展性。
存在问题与挑战#
目前静态图加上 AI 编译器的流程,采用先编译后执行的方式,编译阶段与执行阶段分离,使用前端语言构建的神经网络模型经过编译后,产生固定的计算图结构,在执行阶段不再改变。
使用前端语言编写神经网络模型以及定义模型训练过程的代码较为繁琐,掌握图控制流的方法具有一定的学习成本,因此熟练掌握并使用静态图的模式对初学者并不友好。并且,经过若干优化过程,用于执行的计算图结构与原始代码定义产生的计算图结构有较大差距,导致难以定位到代码中错误的准确位置,增加了代码的调试难度,在神经网络模型的开发迭代环节,不能够即时打印中间结果。
如果需要在源代码中添加输出中间结果的代码,需要将源代码重新编译,再调用执行器才能获取相关信息,降低了代码的调试效率。
围绕 AI 编译器的计算图相关内容,本节将提出两个尚未有明确答案的问题,这些问题或许能激发读者的思考:
PyTorch 的 TorchDynamo 具有良好的设计和较为完善的功能,它可以解决多少实际问题,能够解决 99% 的场景下的问题吗?
MindSpore 的优化主要针对静态图+AI 编译器的模式,对于动态图转静态图与 AI 编译器结合的模式,是否有更好的方案?
小结与思考#
计算图的基本构成:计算图是 AI 框架中表示神经网络计算逻辑的有向无环图(DAG),由张量(Tensor)和算子(Operator)构成,反映计算依赖关系。
AI 框架生成计算图:AI 框架通过自动微分技术,结合静态或动态图生成方法,构建包含正向和反向传播的完整计算图,优化执行性能。
计算图对 AI 编译器的作用:计算图为 AI 编译器提供了优化的基础,允许进行系统级优化,提高执行效率,并支持模型的序列化和硬件部署。