CPU 计算时延#
CPU(中央处理器)是计算机的核心组件,其性能对计算机系统的整体性能有着重要影响。CPU 计算时延是指从指令发出到完成整个指令操作所需的时间。理解 CPU 的计算时延对于优化计算性能和设计高效的计算系统至关重要。在这一节我们将要探讨 CPU 的计算时延组成和影响时延产生的因素,并深入讨论 CPU 计算的时延产生。
内存、带宽与时延关系#
在讨论 CPU 计算时延时,我们需要深入理解内存、带宽和时延之间的关系,因为它们共同影响着计算机系统的性能表现。
内存和带宽的关系:内存的速度和系统带宽共同决定了数据在 CPU 和内存之间的传输效率。更高的内存带宽允许更多的数据在单位时间内传输,从而减少内存的访问时延。
带宽和时延的关系:高带宽通常能够减少数据传输所需的时间,因此可以间接降低时延。然而,增加带宽并不总是能线性减少时延,因为时延还受到其他因素的影响(如数据处理的复杂度和传输距离)。在低带宽环境下,时延会显著增加,因为数据需要更长时间才能传输到目的地,尤其在需要传输大数据量时更为明显。
内存和时延的关系:内存的速度和延迟直接影响 CPU 的访问时间。低延迟的内存允许更快的数据传输和指令处理,从而减少了 CPU 的等待时间和总体计算时延。内存的类型和架构(如 DDR 与 SRAM,单通道与双通道)也会影响访问延迟。优化内存配置可以显著降低时延,提高系统性能。
CPU 计算时延#
下面将介绍 CPU 计算延时的组成和影响计算时延的相关因素。
CPU 计算时延组成#
CPU 计算时延主要由以下几个部分组成:
指令提取时延(Instruction Fetch Time):指令提取时延是指从内存中读取指令到将其放入指令寄存器的时间。这个时延受内存速度和缓存命中率的影响。内存的速度决定了从内存中读取指令的时间。更高速度的内存能够减少提取指令的时间。缓存层次结构(L1, L2, L3 缓存)会极大地影响提取时间。如果指令在缓存中命中,则可以快速获取,否则必须从较慢的主存储器中读取。
指令解码时延(Instruction Decode Time):指令解码时延是指将从内存中读取的指令翻译成 CPU 能够理解的操作的时间。这个时延受指令集架构和解码逻辑复杂性影响。复杂指令集架构(CISC)通常有更长的解码时延,因为指令更复杂;相比之下,精简指令集架构(RISC)由于指令简洁,解码时延较短。解码单元的设计和复杂性也影响解码时延。更复杂的解码逻辑可能处理更多指令类型,但会增加时延。
执行时延(Execution Time):执行时延是指 CPU 实际执行指令所需的时间。这个时延取决于指令的类型和 CPU 的架构,指令类型中不同的指令需要不同的执行时间。例如,简单的算术运算可能只需一个时钟周期,而复杂的浮点运算可能需要多个周期。而 CPU 架构中流水线深度、并行处理能力和指令重排序等技术都会影响指令的执行时延。
存储器访问时延(Memory Access Time): 存储器访问时延是指 CPU 访问主存储器或缓存所需的时间。这个时延受缓存层次结构(L1, L2, L3 缓存)和内存带宽的影响。多级缓存(L1, L2, L3)可以减少访问主存储器的次数,从而降低访问时延。较高的缓存命中率会显著减少时延。内存带宽中高内存带宽支持更快的数据传输,减少访问时延。
写回时延(Write-back Time):写回时延是指执行完指令后将结果写回寄存器或存储器的时间。这一过程也受缓存的影响。CPU 使用写回策略时,数据在更高级别的缓存中更新,而不是立即写入主存储器,从而减少写回时延,而且在多处理器系统中,缓存一致性协议确保各处理器的缓存一致性,这也会影响写回操作的时延。
影响计算时延因素#
CPU 时钟频率(Clock Frequency):时钟频率越高,CPU 处理指令的速度越快,从而减少计算时延。然而,增加时钟频率会增加功耗和发热,需要有效的散热机制。
流水线技术(Pipelining):流水线技术将指令执行分为多个阶段,每个阶段可以并行处理不同的指令,从而提高指令吞吐量,降低时延。但流水线的深度和效率对时延有直接影响。
并行处理(Parallel Processing):多核处理器和超线程技术允许多个指令同时执行,显著降低计算时延。并行处理的效率依赖于任务的可并行性。
缓存命中率(Cache Hit Rate): 高缓存命中率可以显著减少存储器访问时延,提高整体性能。缓存失效(Cache Miss)会导致较高的存储器访问时延。
内存带宽(Memory Bandwidth):高内存带宽可以减少数据传输瓶颈,降低存储器访问时延,提升计算性能。
优化计算时延方法#
优化 CPU 计算时延是一个复杂的过程,需要综合考虑指令提取、解码、执行、存储器访问和写回等多个方面的因素。通过提高时钟频率、优化流水线设计、增加缓存容量、采用高效的并行算法和提升内存子系统性能,可以显著降低 CPU 计算时延,提升计算机系统的整体性能。
提高时钟频率:在不超出散热和功耗限制的情况下,通过提高 CPU 的时钟频率可以直接减少计算时延。
优化流水线深度:适当增加流水线深度,提高指令并行处理能力,但需要平衡流水线的复杂性和效率。
增加缓存容量:增加 L1、L2、L3 缓存的容量和优化缓存管理策略,可以提高缓存命中率,减少存储器访问时延。
使用高效的并行算法:开发和采用适合并行处理的算法,提高多核处理器的利用率,降低计算时延。
提升内存子系统性能:采用高速内存技术和更高带宽的内存接口,减少数据传输时延,提高整体系统性能。
CPU 时延计算#
图中展示了一个简单的 C 代码示例,用于计算
y[i] = alpha * x[i] + y[i]:
void demo(double alpha, double *x, double *y)
{
int n = 2000;
for (int i = 0; i < n; ++i)
{
y[i] = alpha * x[i] + y[i];
}
}
例子解析#
CPU 指令执行过程如下图所示, 图片中的横轴(Times)表示时间的推进。纵轴则展示了不同操作(如加载、计算、写入)的时延。
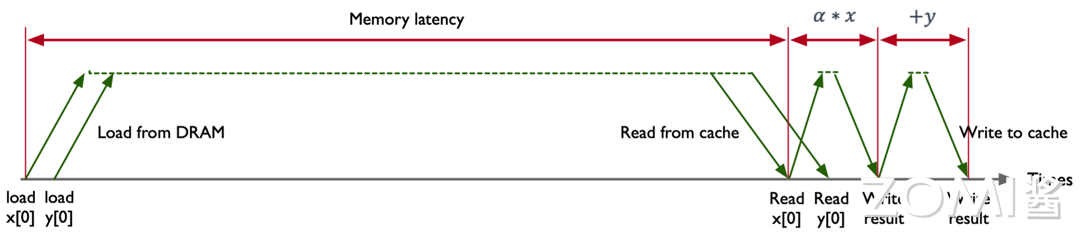
数据加载
Load from DRAM:图片中 Load from DRAM 表示从主存储器(DRAM)加载数据到缓存中,这是开始时的重要步骤。此处的数据包括 x[0] 和 y[0]。由于主存储器与 CPU 之间的速度差异较大,加载数据的时间主要受到较高的内存时延(Memory Latency)的影响。在图中,加载过程展示为从 load x[0]和 load y[0]开始,显示了较长的时间跨度,因为从 DRAM 加载数据到缓存(Cache)的时延相对较长。
缓存读取
Read from cache:图片中的 Read from cache 表示缓存的读取,一旦数据被加载到缓存中,随后的操作大部分是从缓存中读取。这显著减少了时延,因为缓存的访问速度远远快于主存储器。在图中,这一过程表示为读取数据 x[0] 和 y[0],标注了较短的时间跨度,体现了缓存读取的高效性。
计算过程
Read x[0] 和 Read y[0]:在计算开始之前,CPU 需要从缓存中读取要操作的数值 x[0] 和 y[0]。这一阶段也显示了缓存读取的快速性。然后进行乘法运算,计算 α * x。这是 CPU 的执行阶段之一,乘法操作通常被快速执行。接着进行加法运算,将前一步的乘法结果与 y[0] 相加。这一步完成了指令中的加法操作,
写回结果
Write result:将将计算结果写回到缓存中。此步骤展示了计算完结果后的写入操作。写回缓存的过程较为快速,但依然涉及一定的时延。如果有必要,计算结果可能需要从缓存写回到主存储器。也就是 Write to cache。
时延分析#
Memory latency:图中用红色标注的长箭头表示内存时延,即从开始加载数据到数据被缓存所需的总时间。这是影响计算速度的重要因素。
计算时延:乘法和加法操作各自有独立的时延,分别用红色小箭头标注。
缓存操作时延:读取和写入缓存的时延相对较短,用绿色箭头表示。
时延产生#
CPU 时延的产生可以归因于多种因素,包括硬件设计、内存访问和系统资源竞争等。我们将结合这张图和进一步的解释来深入探讨。
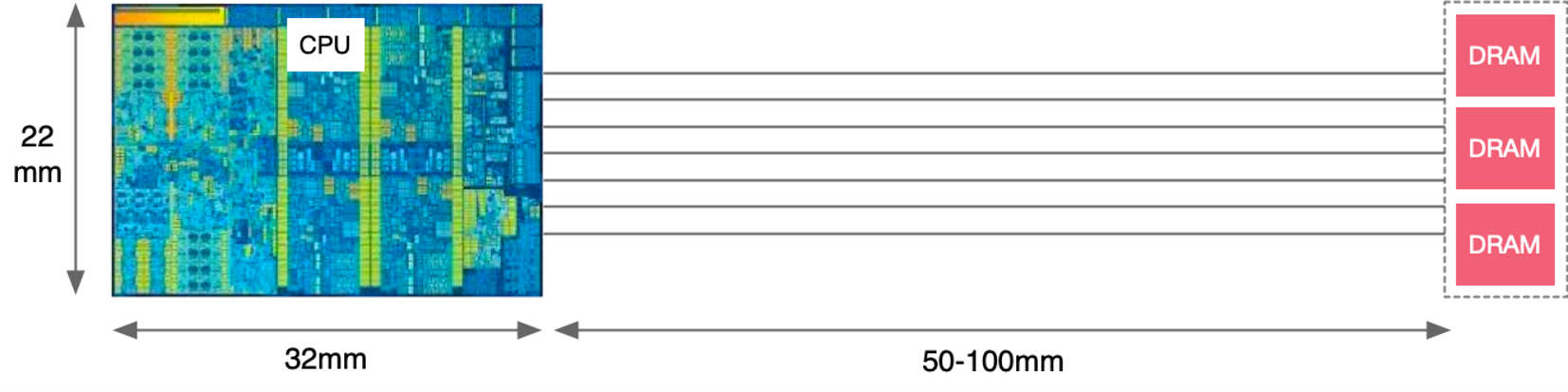
图中显示了 CPU 和 DRAM 之间存在一定的物理距离。在实际硬件中,数据需要在这个距离上通过内存总线进行传输。虽然电信号在这种短距离上的传播速度非常快(接近光速),但仍然会产生可测量的延迟。这个延迟是内存访问时延的一部分。
假设计算机时钟频率为 3,000,000,000 赫兹(3 GHz),意味着每个时钟周期大约为 1 / 3,000,000,000 秒 ≈ 0.333 纳秒,电信号在导体中的传播速度约为 60,000,000 米/秒,根据上图可知,从芯片到 DRAM 的信号传输距离大约为 50-100 毫米,
电信号在 50 毫米的距离上传播的延迟:
电信号在 50 毫米的距离上传播的延迟约为 0.833 纳秒,这相当于 0.833 纳秒 / 0.333 纳秒 ≈ 2.5 个时钟周期。
电信号在 100 毫米的距离上传播的延迟:
电信号在 100 毫米的距离上传播的延迟约为 1.667 纳秒,这相当于 1.667 纳秒 / 0.333 纳秒 ≈ 5 个时钟周期。
这些传播延迟就是 CPU 的时钟周期,也是 CPU 计算的时延。
计算速度因素#
计算速度由多个因素决定,包括内存时延、缓存命中率、计算操作效率和数据写回速度。在图中,决定性因素是内存时延(Memory Latency)。内存时延是指从主存储器(DRAM)读取数据到缓存的固有延迟。由于主存储器的速度远低于缓存和 CPU 寄存器,这一过程通常是最耗时的部分
内存时延的影响
图中显示的数据加载操作(Load from DRAM)占用了很长的时间,突出展示了内存时延的影响。在 load x[0]和 load y[0]阶段,CPU 必须等待数据从主存储器加载到缓存。直到数据加载完成,CPU 无法进行后续的计算操作。
计算过程的阻滞
高内存时延显著延缓了整个计算过程的启动。虽然后续的计算(乘法和加法)以及缓存的读取和写入操作时间较短,但由于内存时延过长,整体计算速度被显著拖慢。CPU 在等待数据加载的过程中,资源被浪费,无法高效地执行计算任务。
小结与思考#
CPU 计算时延是指令从发出到完成操作所需的时间,它由指令提取、解码、执行、存储器访问和写回等环节组成,对优化计算性能和设计高效计算系统至关重要。
内存速度、带宽和延迟直接影响 CPU 的访问时间,优化内存配置如增加缓存容量和提升内存带宽可以显著降低时延,提高系统性能。
降低 CPU 计算时延的方法包括提高时钟频率、优化流水线设计、增加缓存容量、采用高效的并行算法和提升内存子系统性能,这些措施可以提升计算机系统的整体性能。