Tensor Core 架构演进#
自 Volta 架构时代起,英伟达的 GPU 架构已经明显地转向深度学习领域的优化和创新。2017 年,Volta 架构横空出世,其中引入的张量核心(Tensor Core)设计可谓划时代之作,这一设计专门针对深度学习计算进行了优化,通过执行融合乘法加法操作,大幅提升了计算效率。与前一代 Pascal 架构相比,Volta 架构在深度学习训练和推理方面的性能提升了 3 倍,这一飞跃性进步为深度学习的发展提供了强大的硬件支持。
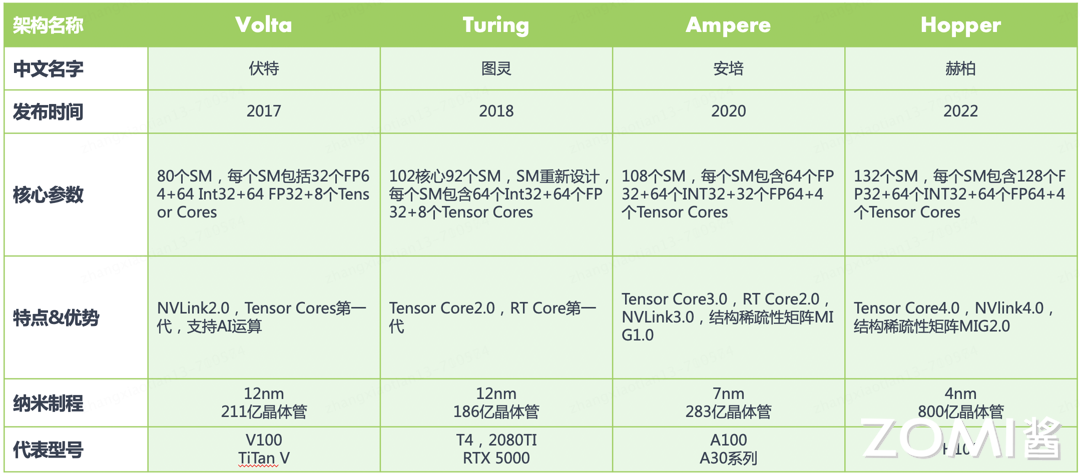
紧随其后,在一年后的 2018 年,英伟达发布了 Turing 架构,进一步增强了 Tensor Core 的功能。Turing 架构不仅延续了对浮点运算的优化,还新增了对 INT8、INT4、甚至是 Binary(INT1)等整数格式的支持。这一举措不仅使大范围混合精度训练成为可能,更将 GPU 的性能吞吐量推向了新的高度,较 Pascal GPU 提升了惊人的 32 倍。此外,Turing 架构还引入了先进的光线追踪(RT Core)技术。
2020 年,Ampere 架构的推出再次刷新了人们对 Tensor Core 的认知。Ampere 架构新增了对 TF32 和 BF16 两种数据格式的支持,这些新的数据格式进一步提高了深度学习训练和推理的效率。同时,Ampere 架构引入了对稀疏矩阵计算的支持,在处理深度学习等现代计算任务时,稀疏矩阵是一种常见的数据类型,其特点是矩阵中包含大量零值元素。传统的计算方法在处理这类数据时往往效率低下,而 Ampere 架构通过专门的稀疏矩阵计算优化,实现了对这类数据的高效处理,从而大幅提升了计算效率并降低了能耗。此外,Ampere 架构还引入了 NVLink 技术,这一技术为 GPU 之间的通信提供了前所未有的高速通道。在深度学习等需要大规模并行计算的任务中,GPU 之间的数据交换往往成为性能瓶颈。而 NVLink 技术通过提供高带宽、低延迟的连接,使得 GPU 之间的数据传输更加高效,从而进一步提升了整个系统的计算性能。
到了 2022 年,英伟达发布了专为深度学习设计的 Hopper 架构。Hopper 架构标志性的变化是引入了 FP8 张量核心,这一创新进一步加速了 AI 训练和推理过程。值得注意的是,Hopper 架构去除了 RT Core,以便为深度学习计算腾出更多空间,这一决策凸显了英伟达对深度学习领域的专注和投入。此外,Hopper 架构还引入了 Transformer 引擎,这使得它在处理如今广泛应用的 Transformer 模型时表现出色,进一步巩固了英伟达在深度学习硬件领域的领导地位。
2024 年,英伟达推出了 Blackwell 架构为生成式 AI 带来了显著的飞跃。相较于 H100 GPU,GB200 Superchip 在处理 LLM 推理任务时,性能实现了高达 30 倍的惊人提升,同时在能耗方面也实现了高达 25 倍的优化。其中 GB200 Superchip 能够组合两个 Blackwell GPU,并与英伟达的 Grace 中央处理单元配对,支持 NVLink-C2C 互联。此外,Blackwell 还引入了第二代 Transformer 引擎,增强了对 FP4 和 FP6 精度的兼容性,显著降低了模型运行时的内存占用和带宽需求。此外,还引入了第五代 NVLink 技术,使每个 GPU 的带宽从 900 GB/s 增加到 1800 GB/s。
总的来说,从 Volta 到 Blackwell,英伟达的 GPU 架构经历了一系列针对深度学习优化的重大创新和升级,每一次进步都在推动深度学习技术的边界。这些架构的发展不仅体现了英伟达在硬件设计方面的前瞻性,也为深度学习的研究和应用提供了强大的计算支持,促进了 AI 技术的快速发展。
接下来,我们将逐一深入剖析每一代 Tensor Core 的独特之处,以揭示其背后的技术奥秘。
第一代 Tensor Core(Volta)#
在开始介绍 Volta 架构中的第一代 Tensor Core 之前,我们先来了解一下 Volta 架构的实现细节。
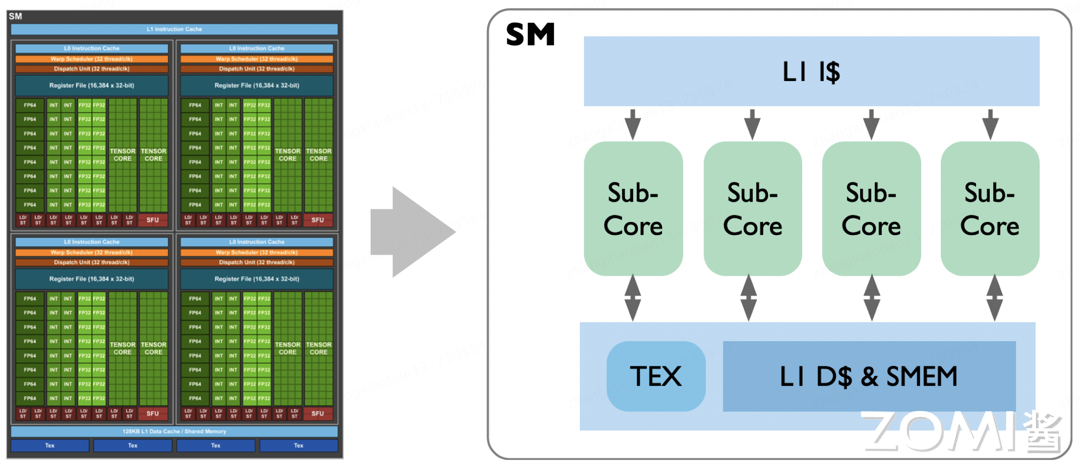
如上图所示,左边就是 Volta SM 的架构图,Volta 架构中的 Streaming Multiprocessor(SM)通过引入子核心(Sub Core)概念,提升了其执行效率和灵活性。在 Volta 架构中,一个 SM 由 4 个 Sub Core 组成,每个 Sub Core 可以被视为一个更小的、功能完备的执行单元,它们共同工作以提高整体的处理能力。
每个 Sub Core 内部包含了一定数量的 CUDA 核心,这是英伟达 GPU 的基础计算单元,用于执行并行计算任务。除此之外,Sub Core 还集成了专门的整数(INT)和浮点(FP)运算单元,这些单元能够同时进行整数和浮点计算,从而提高计算效率。更重要的是,Sub Core 内还配备了一组张量核心(Tensor Core),这是 Volta 架构的核心创新之一,专为加速深度学习中的矩阵乘法和累加操作而设计,极大地提升了深度学习训练和推理的性能。
Volta SM 的结构揭示了其内部工作机制的细节。SM 顶部的 L1 指令缓存负责存储即将执行的指令,并将这些指令发送到下方的四个 Sub Core 中。这种指令传输是单向的,确保了指令能够高效、有序地分配给每个执行单元。
在 Sub Core 完成计算任务后,其与位于 SM 底部的 L1 数据缓存(L1 Cache)和共享内存(Shared Memory)之间的交互则是双向的。这种设计允许 Sub Core 不仅可以读取下一批计算所需的数据,还可以将计算结果写回缓存或共享内存中,供其他 Sub Core 或 SM 中的其他组件使用。这种灵活的数据交互机制优化了数据流动,减少了内存访问延迟,进一步提升了整体的计算效率。
Volta SM 微架构#
接下来我们深入研究 Volta GPU 中的 SM,首先 SM 它在处理寄存器的整体读写逻辑方面起着核心作用,是计算的关键单元。其次在每个 SM 的 Sub-Core 中,包含了多种功能单元,如 Tensor Core(张量核心)、FP64、FP32、INT8 等 CUDA Core、RT Core 和特殊函数处理单元 MFU。
此外,每个 Sub-Core 中还设有 Warp Scheduler,它负责有效调度执行计算单元的工作。数据被存储在寄存器中,通过高效的调度和数据流,实现快速并行的数据处理和计算过程。
值得注意的是,每个 SM Sub-Core 内含有两个 4x4x4 Tensor Core。Warp Scheduler 向 Tensor Core 发送矩阵乘法 GEMM 运算指令。Tensor Core 接收来自寄存器文件的输入矩阵(A、B、C),执行多次 4x4x4 矩阵乘法操作,直至完成整个矩阵乘法,并将结果矩阵写回寄存器文件(Register File)中。
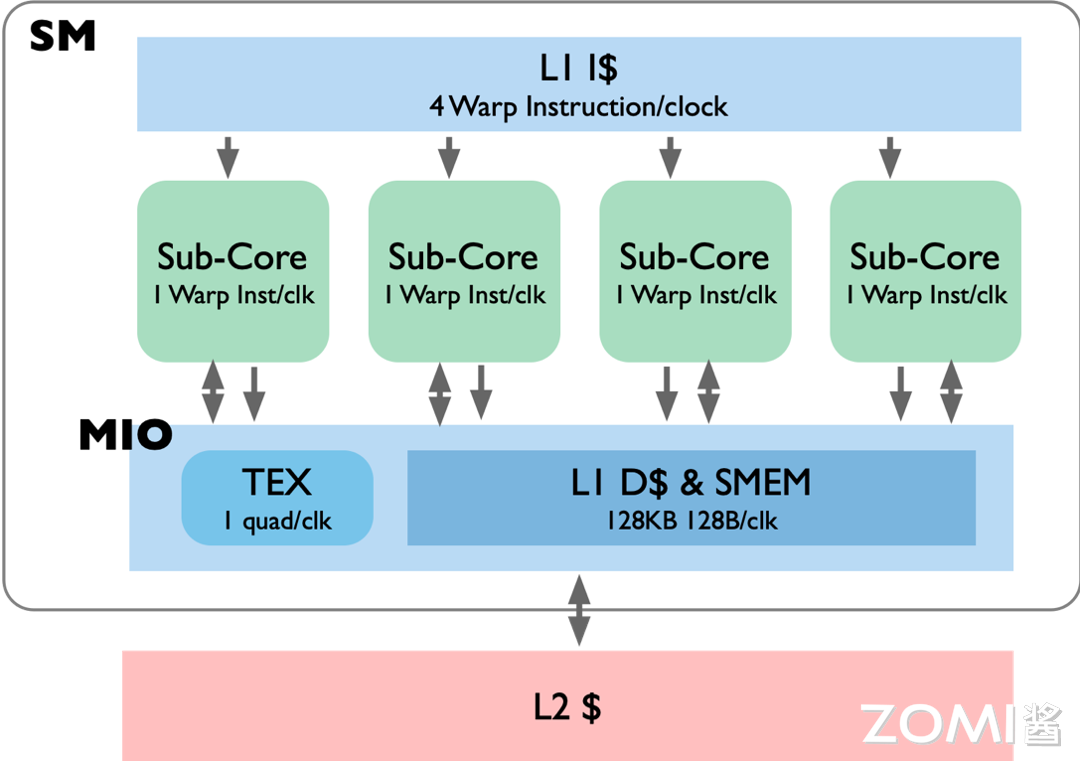
如上图所示,最上面是共享的 L1 缓存,每个时钟周期可以执行 4 个 Warp 指令,下属 4 个独立的 Sub Core 的数据是不进行缓存的,但是每个 Sub Core 里有两个 Tensor Core, 这两个 Tensor Core 中的数据是可以共享的,再往下有一个共享内存,每个时钟周期可以传输 128B 的数据,当所有的 SM 计算完这个权重矩阵就会将数据回传到 L2 Cache 中,最后返回 Host Cpu 中。
Sub Core 微架构#
如图所示,在一个 Sub Core 内的微架构中,顶部依然是 L1 Cache,紧随其后的是 L0 Cache,也就是 Register File。Register File 负责将数据传输到 Warp Scheduler,而具体的指令调度则依赖于 Warp Scheduler。针对通用的矩阵计算任务,即 CUDA Core 计算,我们通过 Math Dispatch Unit 将指令分发到具体的 FP64、INT、FP32 和 MUFU 等执行单元进行计算。
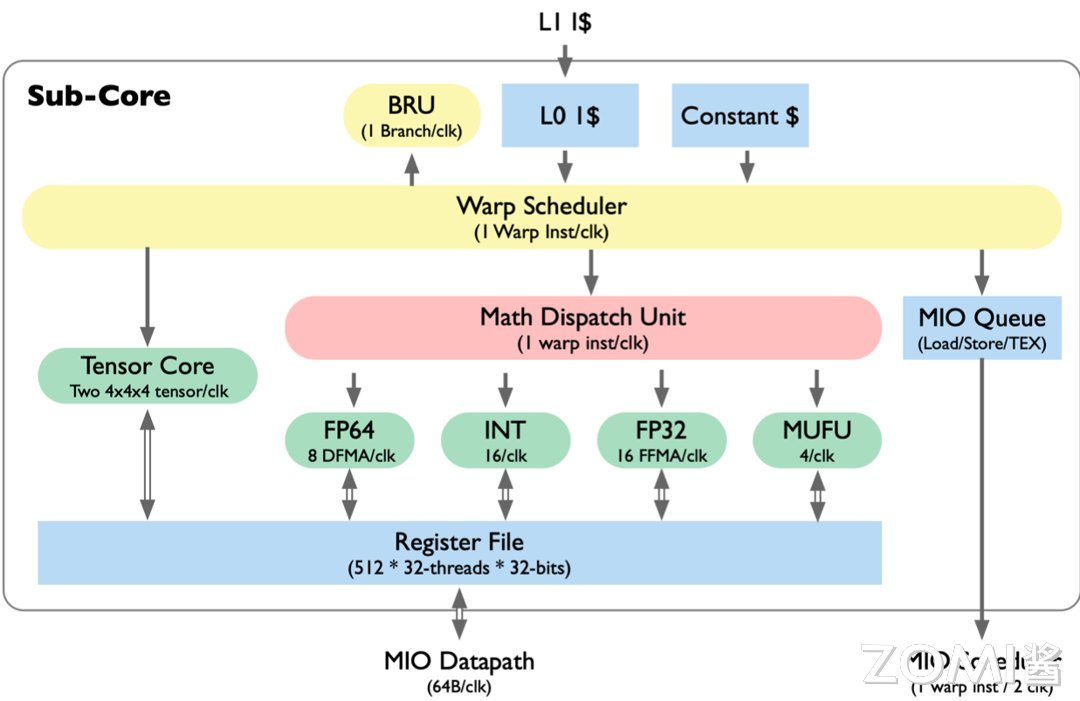
然而,当调用 WMMA 相关的 API 或指令时,Warp Scheduler 会直接触发 Tensor Core 中的计算,每个 Tensor Core 内含有两个 4x4x4 的矩阵,在每个时钟周期内并行进行计算,最终将结果存回 Register File 寄存器中。寄存器通过 MIO 的 Data Pipeline 与 Shared Memory 进行通信。
另外,在 Volta 架构中相比 P100 有一个重要改进,即将 L1 缓存和共享内存合并为同一块空间,其中的共享内存 SMEM 为整个 SM 提供了 96KB 的存储空间。对 L2 Cache 也进行了更新,性能提升了 5%到 15%。
因此,在 Volta 架构中,Sub Core 微架构单独提供了一个 Tensor Core 的指令,直接提供给 Warp Scheduler 使用,无需通过 Math Dispatch Unit 进行指令分发。
除了引入专门针对 AI 框架矩阵计算的 Tensor Core,Volta 架构还减少了指令延迟,进一步提高了计算效率。这些设计和优化使得 Volta 架构对 AI 和深度学习任务有着更快的处理速度。
第二代 Tensor Core(Turing)#
在 Turing 架构中,我们直接进入 Sub Core(微内核)来了解第二代 Tensor Core。
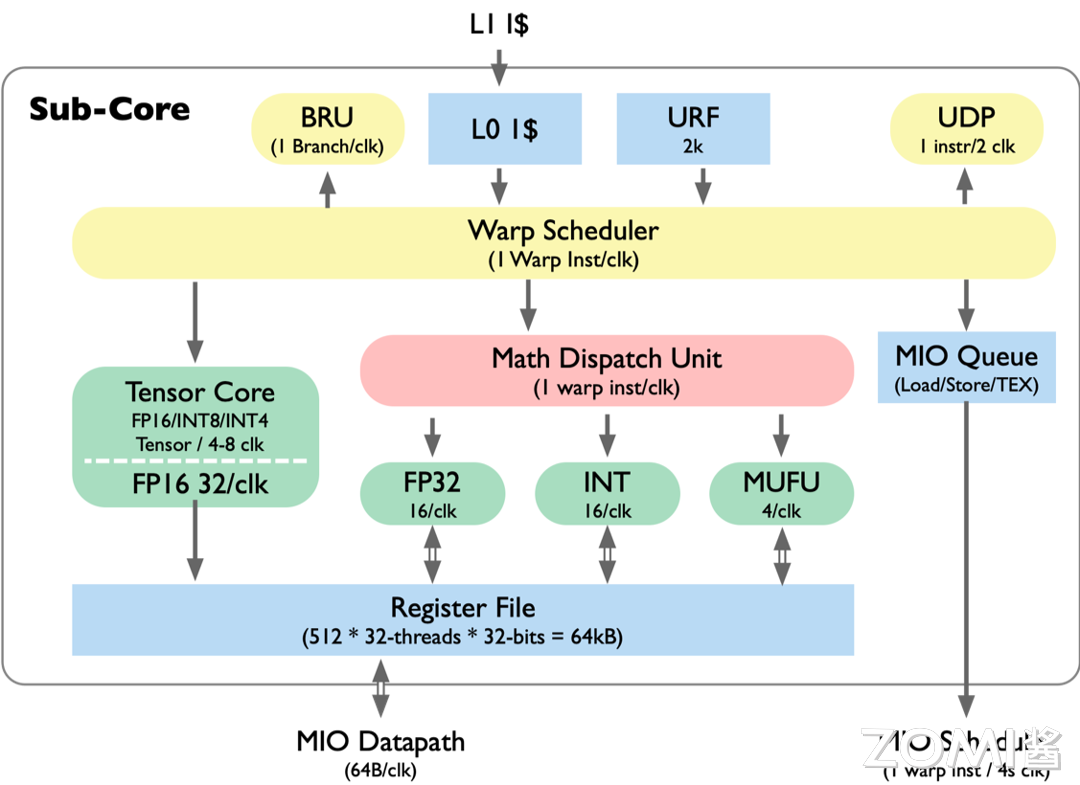
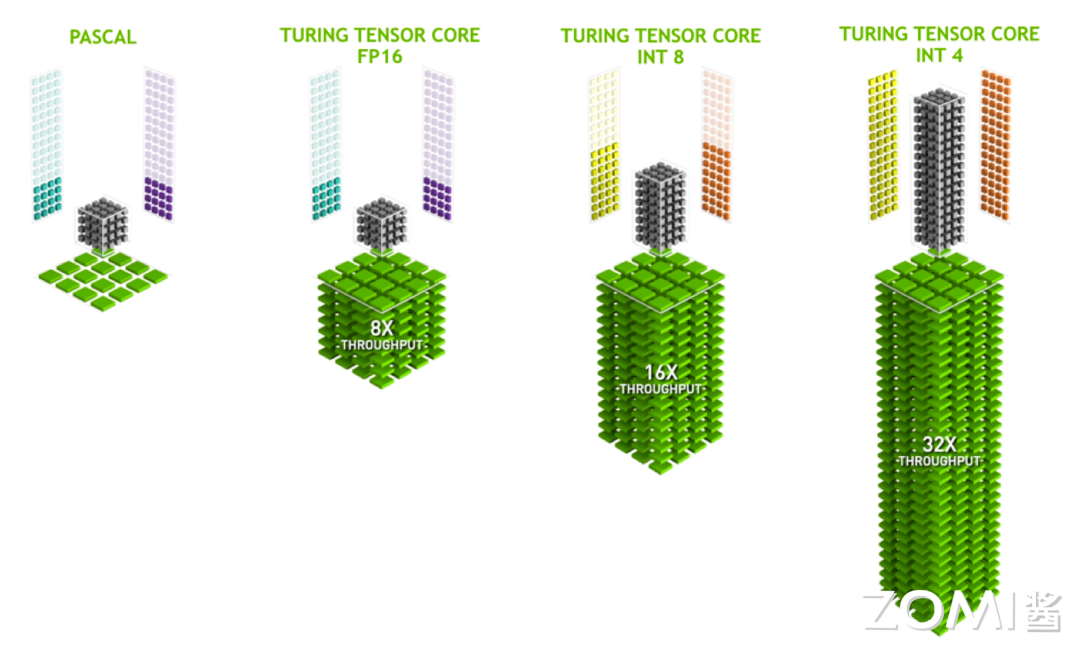
如上图所示,与之前的版本相比,Turing 架构的 Tensor Core 除了支持 FP16 类型之外,还增加了 INT8 和 INT4 等多种类型,这一变化使得 Turing 架构在处理不同精度的计算任务时更加得心应手。
此外,Turing 架构还引入了 FP16 的 FastPath,这一创新设计使得每个时钟周期可以执行高达 32 次的计算操作。与 Volta 架构中需要 4 到 8 个时钟周期才能完成单个多线程 GEMM 计算的情况相比,Turing 架构的计算频率和吞吐量得到了显著提升。
值得一提的是,Turing 架构还支持通过线程共享数据的本地内存(Local Memory)。换句话说,在 Turing 架构的 Tensor Core 层面,每个线程的私有寄存器被设计成了可共享的资源。通过一种透明的共享机制,Tensor Core 能够充分利用这些寄存器资源,实现更高效的矩阵计算。这种设计使得 Tensor Core 在执行矩阵乘法等计算密集型任务时,能够充分利用线程间的协作,提高计算效率,还降低了系统的整体能耗。
Turing 架构的第二代 Tensor Core 在距离上一代 Volta 架构仅一年的时间内推出,它不仅在数据类型支持上进行了扩展,还在计算效率和数据共享方面实现了优化更新。
第三代 Tensor Core(Ampere)#
当谈及第三代 Tensor Core 的重大改变时,首先需要提到多级缓存和数据带宽方面的优化,下面我们就先来具体了解一下 GPU 中的多级带宽体系。
Ampere 多级带宽体系#
如图所示为 Ampere 架构多级带宽体系,我们从下往上看,最下面为这次架构升级所引入 NVLink 技术,它主要来优化单机多块 GPU 卡之间的数据互连访问。在传统的架构中,GPU 之间的数据交换需要通过 CPU 和 PCIe 总线,这成为了数据传输的瓶颈。而 NVLink 技术允许 GPU 之间直接进行高速的数据传输,极大地提高了数据传输的效率和速度。
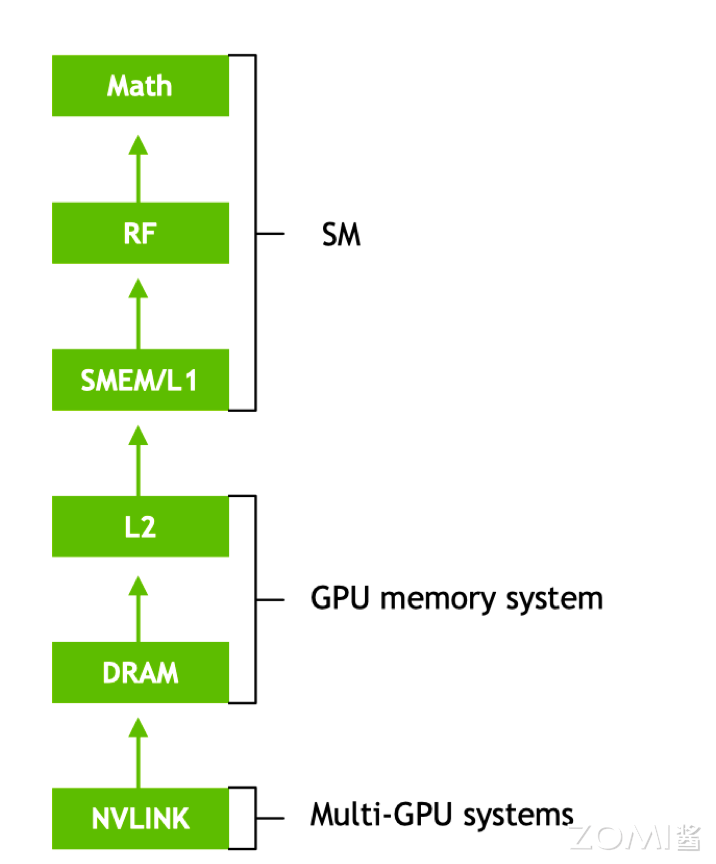
接下来,再往上一层为 L2 Cache 缓存和 DRAM,它们负责的是每块 GPU 卡内部的存储。L2 Cache 缓存作为一个高速缓存,用于存储经常访问的数据,以减少对 DRAM 的访问延迟。DRAM 则提供了更大的存储空间,用于存储 GPU 计算所需的大量数据。这两者的协同工作,使得 GPU 能够高效地处理大规模数据集。这里要说明的一点是我们所说的 HBM 其实就是多个 DRAM 的堆叠,它通过堆叠多个 DRAM 芯片来提高带宽和容量。
再往上一层为共享内存和 L1 Cache,它们负责 SM 中数据存储,共享内存允许同一 SM 内的线程快速共享数据,通过共享内存,线程能够直接访问和修改共享数据,从而提高了数据访问的效率和并行计算的性能。L1 缓存,主要用于缓存 SM 中经常访问的数据和指令。
而最上面是针对具体的计算任务 Math 模块,负责 GPU 数学处理能力。Math 模块包括 Tensor Core 和 CUDA Core,分别针对不同的计算需求进行优化。Tensor Core 是专为深度学习等计算密集型任务设计的,能够高效地执行矩阵乘法等张量运算。而 CUDA Core 则提供了更广泛的计算能力,支持各种通用的 GPU 计算任务。
Movement Efficiently#
在 A100 中,最显著的改进之一是"Movement Efficiently",即数据搬运效率的提升,实现了三倍的速度提升,这主要得益于 Ampere 架构引入的异步内存拷贝机制。
在 Ampere 之前的 GPU 架构中,如果要使用共享内存(Shared Memory),必须先把数据从全局内存(Global Memory)加载到寄存器中,然后再写入共享内存。这不仅浪费了宝贵的寄存器资源,还增加了数据搬运的时延,影响了 GPU 的整体性能。
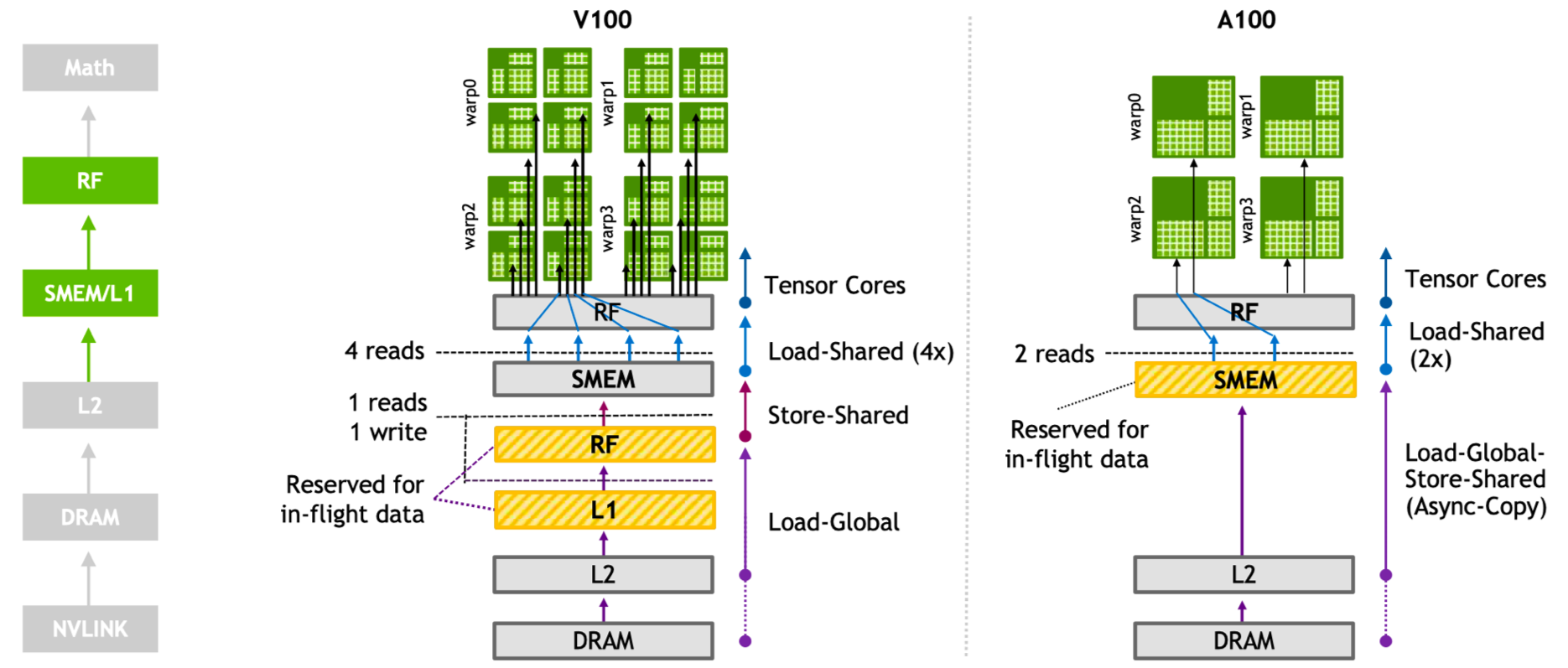
如上图所示,Ampere 架构中提供异步内存拷贝机制,通过新指令 LDGSTS(Load Global Storage Shared),实现全局内存直接加载到共享内存,避免了数据从全局内存到寄存器再到共享内存的繁琐操作,从而减少时延和功耗。
另外,A100 还引入了软件层面的 Sync Copy,这是一种异步拷贝机制,可以直接将 L2 Cache 中的全局内存传输到 SMEM 共享内存,然后直接执行,减少了数据搬运带来的时延和功耗。
此外,Ampere 架构的 Tensor Core 还进行了优化,一个 Warp 提供了 32 个线程,相比于 Volta 架构中每个 Tensor Core 只有 8 个线程,这样的设计可以减少线程之间的数据搬运次数,从而进一步提高计算效率。综上所述,A100 相较于 V100 在数据处理和计算效率方面有了显著的提升。
Tensor Core FFMA#
当我们深入研究 FFMA(Fuse Fold Math and Add)操作时,可以从下图中得到更多的信息。在这个图中,绿色的小块代表 Sub Core,也就是之前提到的 Sub Core,而图中连续的蓝色框代表寄存器 Registers。
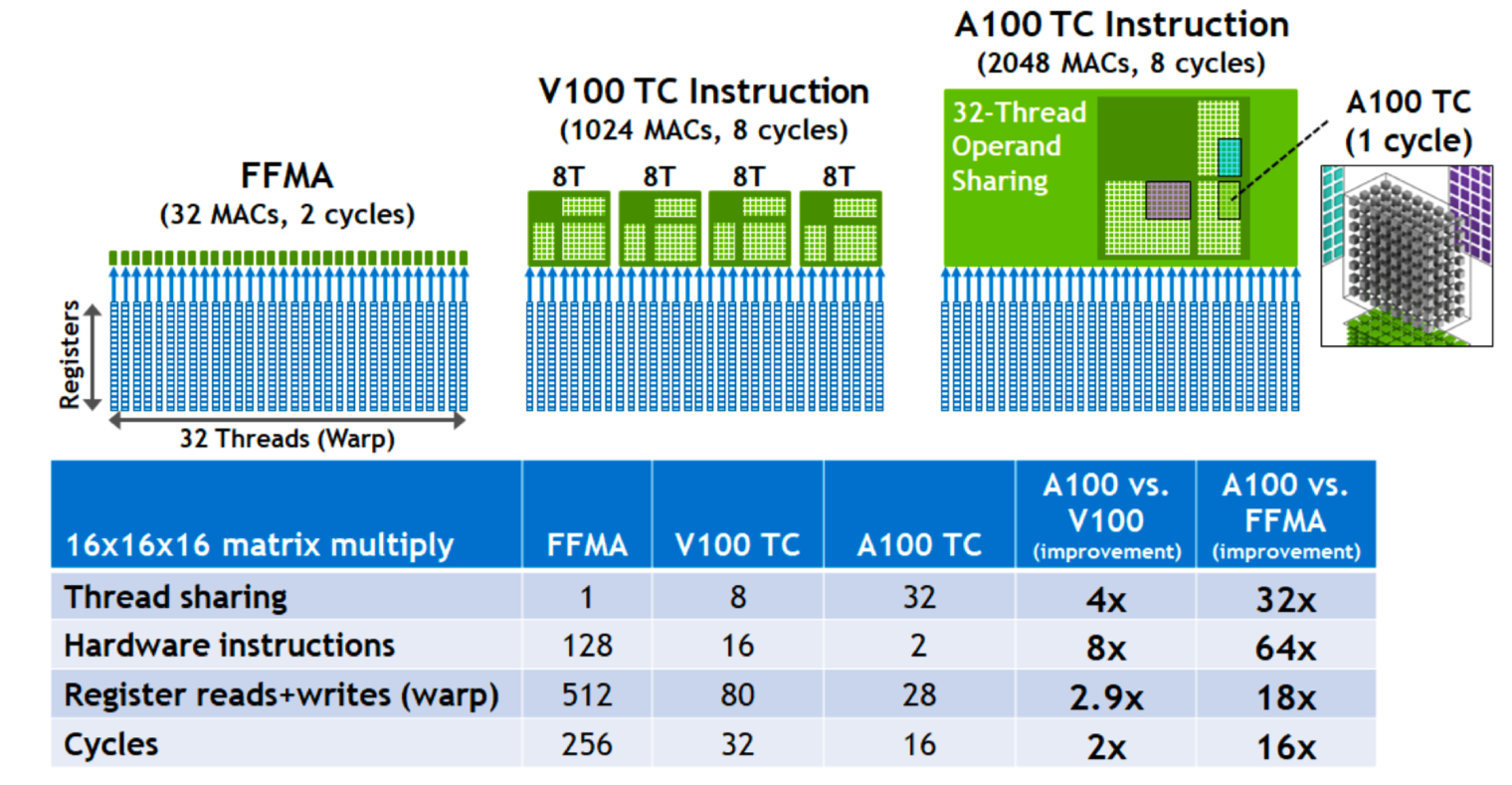
当寄存器仅使用 CUDA Core 时,所有数据都存储在寄存器中,每个寄存器针对一个 CUDA Core 进行数据传输。这样使用 CUDA Core 计算会非常慢。
在 V100 中,每个 Tensor Core 可以处理 8 个线程,每个线程拥有自己的寄存器。因此,在 8 个时钟周期内,可以执行 1024 次 MAC 操作。而在 A100 的 Tensor Core 中,每个 Tensor Core 可以处理 32 条线程,因此在 8 个时钟周期内,可以寄存 2048 次 MAC 操作,每个时钟周期处理其中一块的数据。
第三代 Tensor Core 的 Ampere 架构除了制造工艺的提升外,还提供了更多的线程,使硬件执行速度更快,数据传输更少,每个时钟周期的吞吐量更大。
观察这个图后,我们不禁要问:为什么使用 Tensor Core 比单纯使用 CUDA Core 执行更快呢?
针对矩阵计算而言,这是因为每次针对 Tensor Core 进行计算速度更快、处理更多数据、吞吐量更高。Tensor Core 的引入提高了计算效率,尤其在大规模矩阵计算中表现出色。
第四代 Tensor Core(Hopper)#
2022 年英伟达提出的 Hopper 架构,这一创新架构中最为引人瞩目的便是第 4 代 Tensor Core 的亮相。
回顾 Tensor Core 的发展历程,前三代的 Tensor Core 均基于 Warp-Level 编程模式运作。尽管在英伟达 A100 架构中引入了软件的异步加载机制,但其核心运算逻辑仍基于 Warp-Level 编程模式进行。简而言之,这一模式要求先将数据从 HBM(全局内存)加载到寄存器中,随后通过 Warp Scheduler 调用 Tensor Core 完成矩阵运算,最终再将运算结果回传至寄存器,以便进行后续的连续运算。然而,这一流程中存在两大显著问题。
首先,数据的搬运与计算过程紧密耦合,这导致线程在加载矩阵数据时不得不独立地获取矩阵地址,简而言之,Tensor Core 准备数据时,Warp 内线程分别加载矩阵数据 Data Tile,每一个线程都会获取独立矩阵块地址;为了隐藏数据加载的延时(全局内存到共享内存,共享内存到寄存器的数据加载),会构建多层级软流水(software pipeline),使用更多的寄存器及存储带宽。这一过程不仅消耗了大量的继承器资源,还极大地占用了存储带宽,进而影响了整体运算效率。
其次,这一模式的可扩展性受到了严重限制。由于多级缓存 Cache 的存储空间限制,单个 Warp 的矩阵计算规格有上限,这直接限制了矩阵计算的规模。在大数据、大模型日益盛行的今天,这种限制无疑成为了制约计算性能进一步提升的瓶颈。
而第 4 代 Tensor Core 的引入,正是为了解决这些问题。英伟达通过全新的设计和优化,它旨在实现数据搬运与计算的解耦,提升存储带宽的利用率,同时增强可扩展性,以应对日益复杂和庞大的计算任务。随着第 4 代 Tensor Core 的广泛应用,计算性迎来新的飞跃。
Tensor Memory Accelerator#
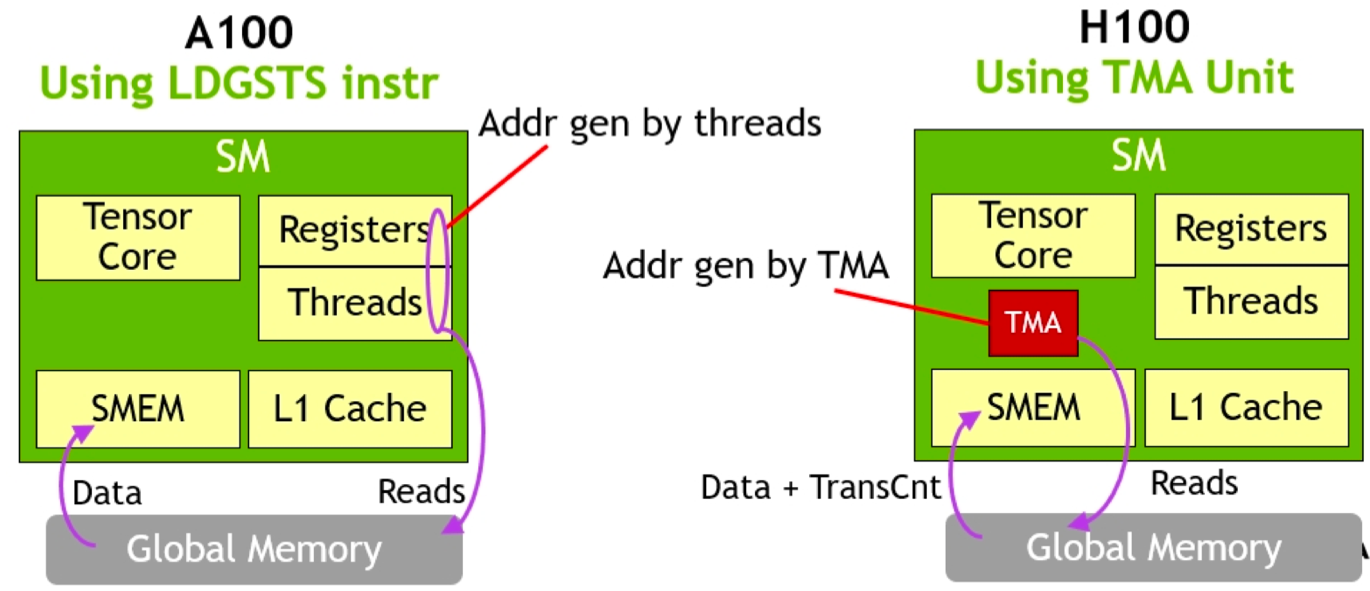
在第 4 代 Tensor Core 中,一个显著的创新是引入了 Tensor Memory Accelerator(简称 TMA),这一功能被称为增量内存加速。这一技术的出现,极大地提升了数据处理效率,为高性能计算领域注入了新的活力。
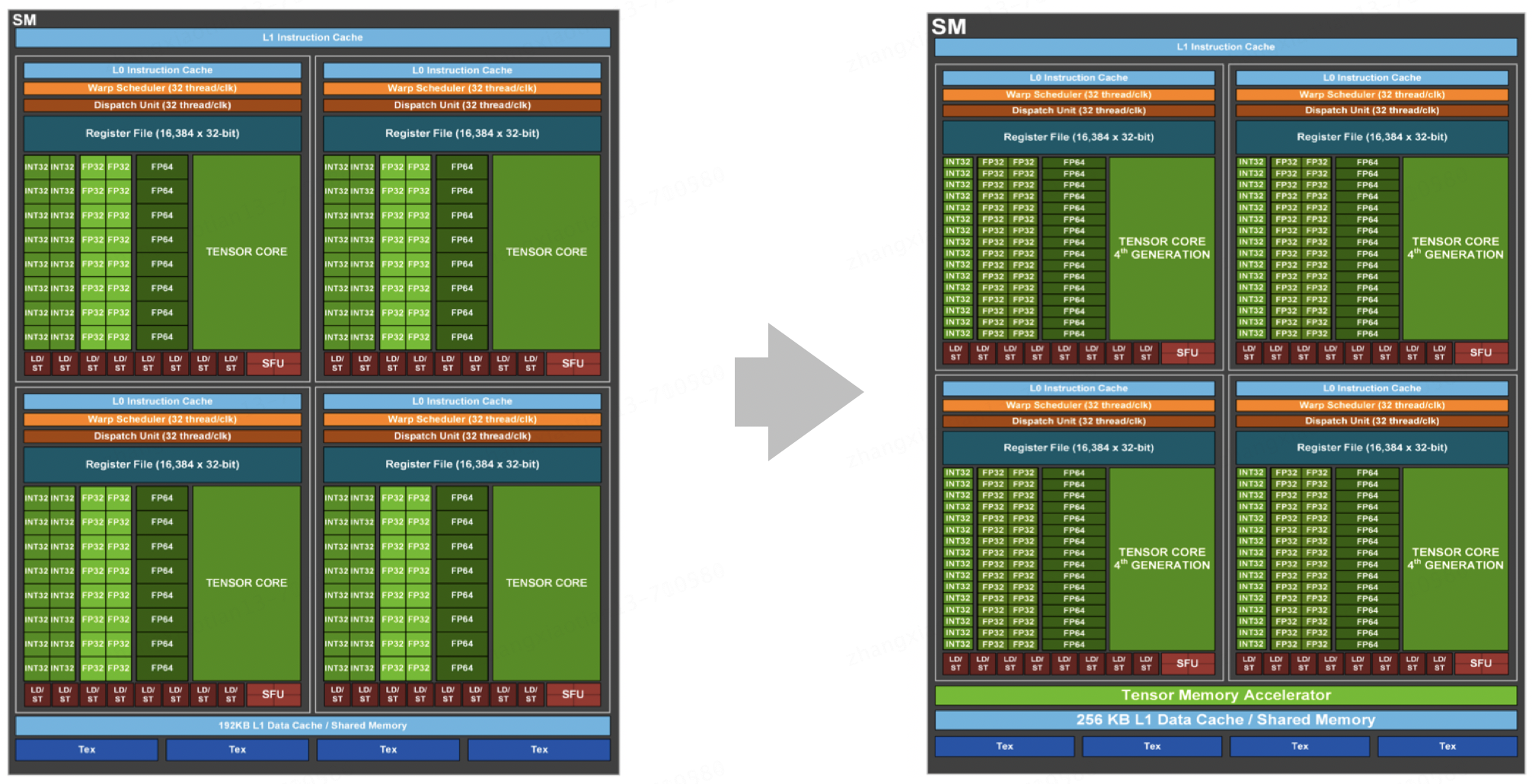
对比 A100 与 H100 的 SM 架构图,如上图所示,我们可以发现二者在结构上并没有太大的差异。然而,由于工艺制程的进步,H100 中的 CUDA Core 和 Tensor Core 的密度得以显著提升。更为重要的是,H100 中新增了 Tensor Memory Accelerator,这一硬件化的数据异步加载机制使得全局内存的数据能够更为高效地异步加载到共享内存,进而供寄存器进行读写操作。
传统的 Warp-Level 编程模式要求所有线程都参与数据搬运和计算过程,这不仅消耗了大量的资源,还限制了计算规模的可扩展性。而单线程 schedule 模型则打破了这一束缚,它允许 Tensor Core 在不需要所有线程参与的情况下进行运算。这种设计大大减少了线程间的同步和协调开销,提高了计算效率。此外,使用 TMA(Tensor Memory Access)之前,用户只需要一次性配置好首地址、偏移量等 Tensor 描述信息。这种一次性配置的方式简化了操作流程,减少了重复配置的开销,使得 Tensor Core 能够更加专注于计算任务本身。
在 A100 时代,虽然已经实现了软件层面的数据异步加载,但 TMA 的硬件化实现无疑将这一功能推向了新的高度。通过 TMA,数据搬运与计算之间的耦合度得以降低,从而提高了整体运算效率。
分布式共享内存和 warp group 编程模式#
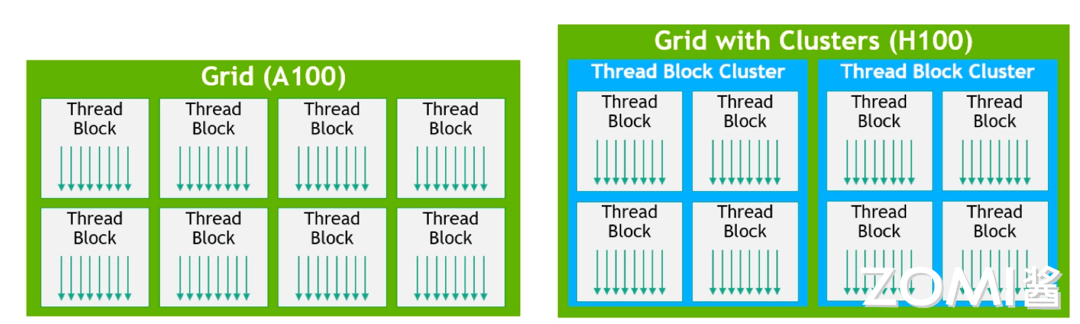
如上图所示,在 H100 之前的架构中,线程的控制相对有限,主要基于 Grid 和 Block 的划分,分别对应硬件 SM 和 Device,且局部数据只能通过 shared memory 限制在 SM 内部,不能跨 SM。然而,在 Hopper 架构中,情况发生了显著变化。通过在硬件层面引入交叉互联网络,数据得以在 4 个 SM 之间进行拓展和共享,GPC 内 SM 可以高效访问彼此的共享内存。这一创新使得 SM 之间能够实现高效的通信,从而打破了之前架构中 SM 间的数据隔阂。
此外,随着硬件架构的变革,软件编程模式也相应发生了调整。Warp group 编程模式的提出,以及与之相关的 Tensor Block Cluster 概念,都体现了软硬件协同优化的思想。这种编程模式能够更好地利用 Hopper 架构的特性,实现更高效的计算性能。
更直观的从软件层面去看一下,有什么区别呢?
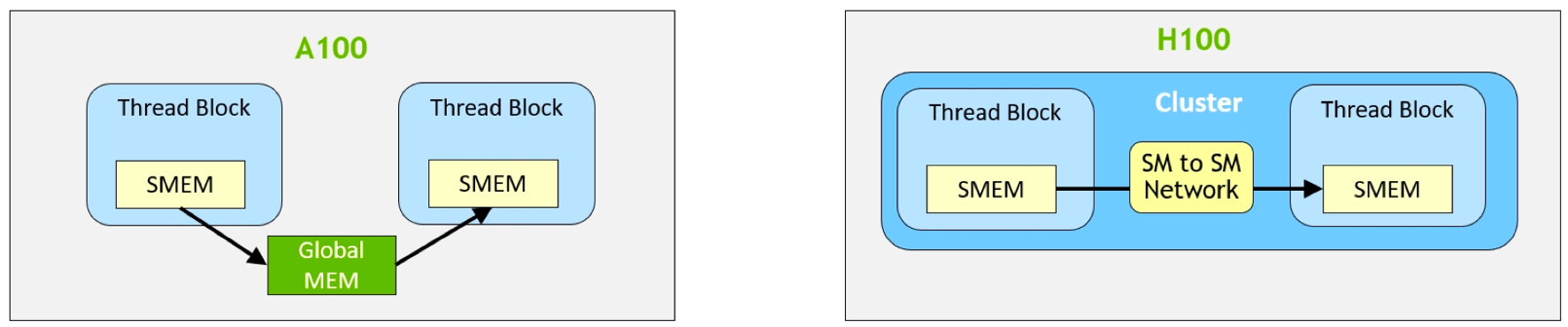
如上图左边所示,没有进行分布式共享内存时每个 Thread Block 都对应一个 SM,每个 SM 内部拥有自己的共享内存。然而,SM 与 SM 之间无法进行直接的数据交互,这意味着它们之间的通信必须通过全局内存进行。这种通信方式不仅增加了数据传输的时延,还可能导致寄存器的过度使用,降低了计算效率。
而在 H100 架构中,如上图右边所示,通过引入 SM 的 Cluster 或 Block 的 Cluster,实现了硬件层面的分布式共享内存。这意味着 SM 与 SM 之间的数据可以直接进行互联,无需再通过全局内存进行中转。这种机制极大地减少了数据传输的时延,提高了数据交互的效率。同时,由于数据可以在 SM 之间直接共享,寄存器的使用也得到了更加合理的分配,减少了不必要的浪费。
此外,通过 TMA 将 SM 组织成一个更大的计算和存储单元,从而实现了数据从全局内存(global memory)到共享内存(shared memory)的异步加载,以及数据到寄存器的计算和矩阵乘法的流水线处理,最后通过硬件实现了矩阵乘法的流水线。硬件实现的矩阵乘法流水线确保了计算过程的连续性和高效性,使得 GPU 能够更快地处理大规模矩阵运算。
第五代 Tensor Core(Blackwell)#
为了更好地适应 AI 工作负载的需求,同时提高性能和降低资源消耗。在 Blackwell 架构中,支持了第五代 Tensor Core,继续扩展了对低精度计算范围支持。第五代 Tensor Core 中,能够处理最低至 FP4 精度,并着眼于使用非常低精度的格式进行推理。与上一代英伟达 Hopper 相比,有着第五代 Tensor Core 支持的 Blackwell 架构可为 GPT-MoE-1.8 T 等大模型提供 30 倍的加速。
此外,为了应对那些 FP4 精度不足以满足的工作负载,第五代 Tensor Core 还增加了对 FP6 精度的兼容。虽然 FP6 精度在计算性能上并不比 FP8 有显著提升,因为它在英伟达的张量核心中本质上仍然是以类似 FP8 的方式进行操作,但由于数据大小缩小了 25%,它在内存占用和带宽需求方面带来了显著的优势。
对于大型语言模型(LLM)的推理任务而言,内存容量依然是这些加速器所面临的主要限制。因此,在推理过程中降低内存使用量成为了一个亟待解决的问题。通过采用低精度格式如 FP4 和 FP6,可以在保持推理质量的同时,有效减少内存消耗,这对于提升 LLM 推理的效率和可行性至关重要。
此外,第五代 Tensor Core 还支持社区定义的微缩放格式 MX(Microscaling)Format ,它是一种精度调整技术,相比一般的 scalar format (比如 FP32, FP16),MX Format 的粒度更高,多个 scalar 构成一组数据(vector format),它允许模型在保持相对高精度的同时减少计算资源的消耗。
MX Format 的核心特点是其由两个主要部分组成:scale(X)和 element(P)。在这种格式中,k 个 element 共享一个相同的 scale。Element 的定义是基于 scalar format,如 FP32、FP16 等。这种设计允许在保持一定精度的同时,通过共享 scale 来减少存储需求和计算开销。此外,我们可以将 MX Format 视为一种不带 shift 的量化方法。量化是一种将连续或高精度数据转换为低精度表示的技术,通常用于减少模型大小和加速推理过程。MX Format 通过引入 block size k 来定义量化的粒度,即每个 block 中的 element 数量。
ze 通常设置为 32,这意味着每个 scale 会影响 32 个 element。MX Format 的优势在于它提供了比传统的 per-tensor 或 per-channel 量化更低的粒度,这有助于在保持计算效率的同时提高精度。然而,这种更细的量化粒度也会带来额外的存储开销。MX Format 的另一个特点是其数据位度的灵活性。例如,MXFP4 格式中,scale bits 为 8,block size 为 32,这意味着每个 scalar 平均占用 12 比特(8 bits for scale + 4 bits for element),这比传统的 FP4 格式提供了更多的信息。总之,MX Format 可以被看作是一种定制的数据表示方式,旨在为特定的硬件平台提供加速。
此外,Blackwell 架构,进一步支持了第二代 Transformer 引擎。第二代 Transformer 引擎与第五代 Tensor Core 技术与 TensorRT-LLM 和 NeMo 框架创新相结合,加速大语言模型 (LLM) 和专家混合模型 (MoE) 的推理和训练,可将性能和效率翻倍,同时为当前和新一代 MoE 模型保持高精度。
小结与思考#
英伟达 GPU 架构自 Volta 起引入 Tensor Core 后,历经五代演进,每代都通过技术创新如 TMA 和分布式共享内存,显著提升了 AI 计算的效率和性能。
五代 Tensor Core 的演进反映了英伟达对深度学习硬件支持的不断加强,特别是对低精度计算和大规模矩阵运算的优化,为 AI 训练和推理提供了更高效的硬件基础。
Blackwell 架构的第五代 Tensor Core 通过支持 FP4 和 FP6 精度计算,以及引入第二代 Transformer 引擎,展现了英伟达面向未来 AI 工作负载需求的前瞻性设计,进一步推动了生成式 AI 和大型语言模型的发展。