EfficientNet 系列#
本节主要介绍 EffiicientNet 系列,在之前的文章中,一般都是单独增加图像分辨率或增加网络深度或单独增加网络的宽度,来提高网络的准确率。而在 EfficientNet 系列论文中,会介绍使用网络搜索技术(NAS)去同时探索网络的宽度(width),深度(depth),分辨率(resolution)对模型准确率的影响。以及如何加速训练推理速度。
EfficientNet V1 模型#
EfficientNetV1:重点分析了卷积网络的深度,宽度和输入图像大小对卷积网络性能表现的影响,提出了一种混合模型尺度的方法,通过设置一定的参数值平衡调节卷积网络的深度,宽度和输入图像大小,使卷积网络的表现达到最好。
复合模型缩放#
单独适当增大深度、宽度或分辨率都可以提高网络的精确性,但随着模型的增大,其精度增益却会降低。此外,这三个维度并不是独立的(如:高分辨率图像需要更深的网络来获取更细粒度特征等),需要我们协调和平衡不同尺度的缩放,而不是传统的一维缩放。EfficientNet 的设想就是能否设计一个标准化的卷积网络扩展方法,既可以实现较高的准确率,又可以充分的节省算力资源。其通过 NAS(Neural Architecture Search)技术来搜索网络的图像输入分辨率 r,网络的深度 depth 以及 channel 的宽度 width 三个参数的合理化配置。如下图所示,(b),(c),(d)分别从不同的维度对 baseline 做 model scaling,而这篇论文要做的是将这 3 者结合起来一起优化即(e)。
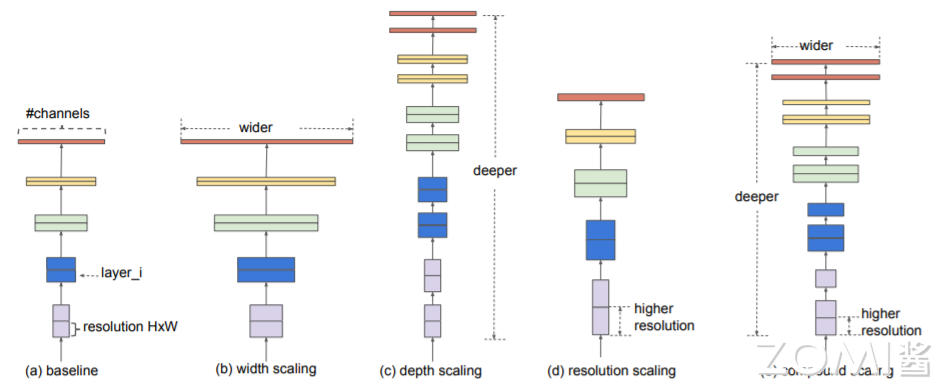
通过实验得出以下结论:
增加网络的 depth 能够得到更加丰富、复杂的高级语义特征,并且能很好的应用到其他任务中去。但是网络的深度过深会面临梯度消失,训练困难等问题。
增加网络的 width 能够获得更高细粒度的特征,并且也更容易训练。但是对于宽度很大,深度较浅的网络往往很难学习到更深层次的特征。例如我就只有一个 3×3 的卷积,但是输出通道为 10000,也没办法得到更为抽象的高级语义。
增加输入网络的图像分辨率能够潜在获得更高细粒度的特征模版,图像分辨率越高能看到的细节就越多,能提升分辨能力。但是对于非常高的输入分辨率,准确率的增益也会减少。且大分辨率图像会增加网络的计算量(注意不是参数量)。
一个卷积网络的某一层 \(i\) 可以被定义为;
其中:\(X_{i}\) 表示输入的 tensor,其形状为 \(<H_{i},W_{i},C_{i}>\),\(Y_{i}\) 是输出的 tensor。于是,一个卷积网络 \(N\) 可以被表示成如下形式:
但是在实际中,ConvNets 的各个层通常被划分为多个 stage,并且每个 stage 中的所有层都具有相同的体系结构(例如 ResNet,共有五个 stage,除了第一层之外的每个 stage 的所有层都分别具有相同的卷积类型)。
因此,我们可以将 ConvNet 重新表示成如下形式: $\( N = \bigoplus_{i=1...s}F_{i}^{L_i}(X_{<H_{i},W_{i},C_{i}>}) \)\( 其中 \)F_{i}^{L_{i}}\( 表示第 \)i\( 个 stage,并且这个 stage 由 \)L_{i}\( 次的 \)F_{i}$(相当于一层 layer)操作构成。
通常 ConvNet 的设计焦点在 \(F_{i}\),但是这篇文章的焦点,或者说 Model Scaling 的焦点则是在模型的深度(\(L_{i}\))、宽度(\(C_{i}\))和输入图片的大小(\(H_{i}\),\(W_{i}\)),而不改变在 baseline 中预先定义好的 \(F_{i}\)。
通过固定 \(F_{i}\),简化了对于新资源约束的 Model Scaling 设计问题,但仍然有很大的设计空间来探索每一层的不同 \(L_{i}\),\(C_{i}\),\(H_{i}\),\(W_{i}\)。为了进一步减小设计空间,作者又限制所有层必须以恒定比率均匀地做 Scaling。目标是在任何给定的资源约束下最大化模型精度,这可以表述为优化问题: $\( max_{d,w,r}Accurracy(N(d,w,r)) \)$
其中:w,d,r 分别为 Model Scaling 的宽度,深度和分辨率的系数,\(\hat {F}_{i}\),\(\hat{L}_{i}\),\(\hat{H}_{i}\),\(\hat{W}_{i}\),\(\hat{C}_{i}\) 是预先设定好的参数。
Scaling Dimensions
上述优化问题主要困难在于:最佳的 d,w,r 是相互依赖的,并且在不同的资源约束下会发生变化。由于这一困难,常规方法通常会在网络深度(layers),宽度(channel)和输入图像的分辨率这三个维度之一来扩展 ConvNets。
Depth:缩放网络深度是一种常用的提高卷积网络精度的方法,但是由于梯度消失问题,更深层次的网络也更难训练。
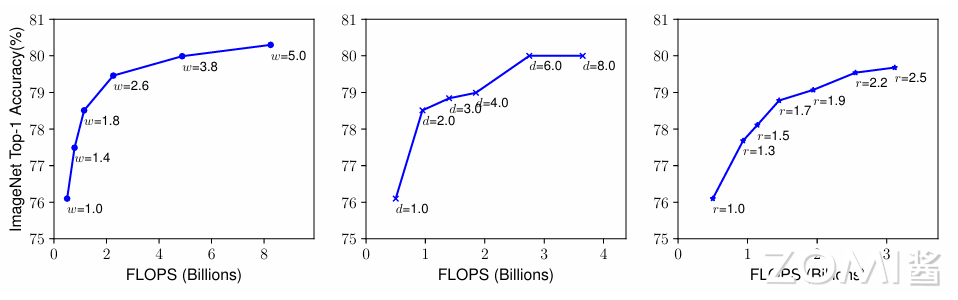
下图左边显示了具有不同深度系数 d 的基线模型进行缩放的实证研究,表明了增加网络层数到一定深度时精度并不能随之增加。
Width:小型模型通常使用缩放网络宽度来提取更多的特征,然而,非常宽但较浅的网络往往难以捕获更高层次的特征。下图中结果显示,当网络越大,w 变得越宽时,精度迅速饱和。
Resolution:早期的图像大小以 224×224 开始,现在常使用 299×299 或者 311×311。最近的创新:480×480 的分辨率和 600×600 的分辨率。下图右是缩放网络分辨率的结果,更高的分辨率的确提高了网络的精度,但对于非常高的分辨率来说,准确率的提高会减弱。
Compound Scaling
为了追求更好的精度和效率,在连续网络缩放过程中平衡网络宽度、深度和分辨率的所有维度是至关重要的。如下图所示。
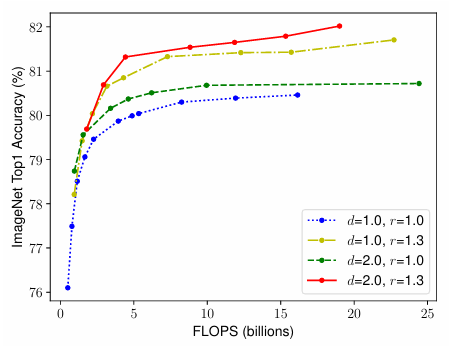
不同维度的 Scaling 并不相互独立,需要协调和平衡不同维度的 Scaling,而不是常规的单维度 Scaling。EfficientNet 提出了 compound scaling method(复合缩放方法),这种方法是通过一个复合系数φ去统一缩放网络的宽度,深度和分辨率,公式表示如下:
其中,α、β以及γ是常数,可以通过在 baseline 上做 small grid search 来得到。ϕ 是用户指定的系数,用于控制有多少其他计算资源可用于模型缩放,而 α,β,γ 指定如何分别将这些额外资源分配给网络宽度,深度和分辨率。
需要注意的是:常规卷积运算的 FLOPS 与 d,\(w^{2}\),\(r^{2}\) 成正比,即网络深度增加 1 倍会使 FLOPS 增加 1 倍,网络宽度或分辨率增加 1 倍会使 FLOPS 增加 4 倍。
由于卷积运算通常在 ConvNets 中占主导地位,因此根据上述的等式,缩放 ConvNets 将使总 FLOPS 大约增加 \((α⋅β^{2}⋅γ^{2})ϕ\)。在本文中,作者做了 \(α⋅β^{2}⋅γ^{2}≈2\) 的约束,这样对于任何新的 ϕ ,总 FLOPS 大约会增加 \(2^{ϕ}\)。
SE 模块#
如下图所示,SE 模块由一个全局平均池化(AvgPooling),两个 FC 层组成。第一个全连接层的节点个数是 MBConv 模块的输入特征图 channels 的 \( \frac{1}{4}\) ,且使用 Swish 激活函数。第二个全连接层的节点个数等于 MBConv 模块中 DWConv 层输出特征图的 channels,且使用 Sigmoid 激活函数。简单理解,SE 模块的总体思想是:给每个特征图不同的权重,关注更有用的特征。
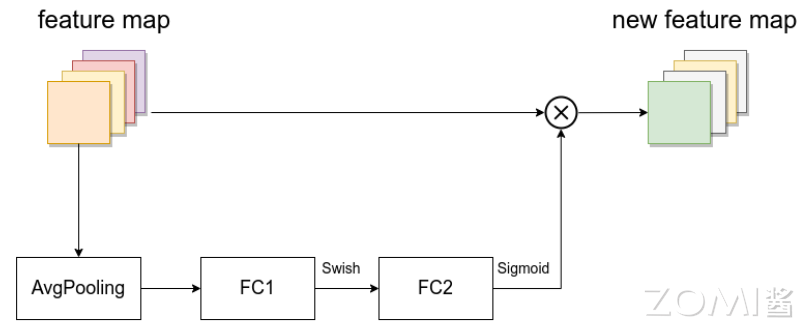
# 注意力机制模块
class SqueezeExcitation(nn.Module):
def __init__(self,
input_c: int, # block input channel # 其对应的是 MBConv 模块输入的 channel
expand_c: int, # block expand channel # 因为之前的 DW 卷积不改变 channe,所以其对应着 1x1 卷积输出的 channel
squeeze_factor: int = 4): # squeeze_c:其等于 input_c 的 channel 数的 1/4
super(SqueezeExcitation, self).__init__()
squeeze_c = input_c // squeeze_factor
self.fc1 = nn.Conv2d(expand_c, squeeze_c, 1) # 此处使用卷积来达到全连接层的目的,所以 kernel_size 为 1 此处与 ModileNet 中的注意力机制的输入 channel 的选择存在差异
self.ac1 = nn.SiLU() # alias Swish
self.fc2 = nn.Conv2d(squeeze_c, expand_c, 1)
self.ac2 = nn.Sigmoid()
def forward(self, x: Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = self.ac1(scale)
scale = self.fc2(scale)
scale = self.ac2(scale)
return scale * x
网络结构实现#
以 EfficientNet-B0 baseline 网络结构为例,在 B0 中一共分为 9 个 stage,表中的卷积层后默认都跟有 BN 以及 Swish 激活函数。stage 1 就是一个 3×3 的卷积层。对于 stage 2 到 stage 8 就是在重复堆叠 MBConv。

Conv 1x1, s1 层,一个 1x1 的标准卷积,用于降维,然后通过一个 BN,没有 swish 激活函数。 Droupout 层,其 dropout_rate 对应的是 drop_connect_rate;shortcut 连接,执行 add 操作。
# MBConvm 模块的配置类
class InvertedResidualConfig:
# kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate
def __init__(self,
kernel: int, # 3 or 5 DW 卷积的 kernel_size,可能为 3x3 或者 5x5
input_c: int, # 表示输入 MBConvm 模块的 channel
out_c: int, # 表示 MBConvm 模块的输出 channel
expanded_ratio: int, # 1 or 6 表示 MBConvm 模块内第一个 1x1 卷积层维度扩展输出的 channel 的扩展因子
stride: int, # 1 or 2 DW 卷积的步距
use_se: bool, # True
drop_rate: float, # # 表示 MBConvm 模块中的丢弃层,随机失活比例
index: str, # 1a, 2a, 2b, ...
width_coefficient: float): # 网络宽度的倍率因子,即 channel 数 xn
self.input_c = self.adjust_channels(input_c, width_coefficient)
self.expanded_c = self.input_c * expanded_ratio # expanded_ratio:1 or 6 表示 MBConvm 模块内第一个 1x1 卷积层维度扩展输出的 channel 的扩展因子
self.kernel = kernel
self.out_c = self.adjust_channels(out_c, width_coefficient)
self.use_se = use_se
self.stride = stride
self.drop_rate = drop_rate
self.index = index
@staticmethod
def adjust_channels(channels: int, width_coefficient: float): # width_coefficient: float): # 网络宽度的倍率因子,即 channel 数 xn
return _make_divisible(channels * width_coefficient, 8)
# MBConvm 模块类
class InvertedResidual(nn.Module):
def __init__(self,
cnf: InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c) # 判断是否进行 shortCut 连接 cnf.stride == 1:表示输出矩阵的高与宽是不会发生变化的
layers = OrderedDict() # 定义一个有序的字典
activation_layer = nn.SiLU # alias Swish
# expand
if cnf.expanded_c != cnf.input_c: # 即当 n(expanded_ratio)=1 时,其不需要升高维度
# MBConv 模块中的第一个 1x1 卷积层
layers.update({"expand_conv": ConvBNActivation(cnf.input_c,
cnf.expanded_c, # 进行升高维度
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# depthwise
layers.update({"dwconv": ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer)})
if cnf.use_se:
# 添加注意力机制
layers.update({"se": SqueezeExcitation(cnf.input_c,
cnf.expanded_c)})
# project
# 注意力机制后,再加一个 1x1 的卷积
layers.update({"project_conv": ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity)}) # 该层之后未使用激活函数,所以使用 nn.Identity,表示不做任何处理,
self.block = nn.Sequential(layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
# 只有在使用 shortcut 连接时才使用 dropout 层
if self.use_res_connect and cnf.drop_rate > 0:
self.dropout = DropPath(cnf.drop_rate)
else:
self.dropout = nn.Identity()
def forward(self, x: Tensor) -> Tensor:
result = self.block(x)
result = self.dropout(result)
if self.use_res_connect:
result += x
return result
EfficientNet V2 模型#
EfficientNet V2:该网络主要使用训练感知神经结构搜索和缩放的组合;在 EfficientNetV1 的基础上,引入了 Fused-MBConv 到搜索空间中;引入渐进式学习策略、自适应正则强度调整机制使得训练更快;进一步关注模型的推理速度与训练速度。
训练感知 NAS 和缩放#
NAS 搜索
这里采用的是 trainning-aware NAS framework,搜索工作主要还是基于之前的 Mnasnet 以及 EfficientNet. 但是这次的优化目标联合了 accuracy、parameter efficiency 以及 trainning efficiency 三个维度。这里是以 EfficientNet 作为 backbone,设计空间包含:
convolutional operation type : MBConv, Fused-MBConv
number of layer
kernel size : 3x3, 5x5
expansion ratio : 1, 4, 6
另外,作者通过以下方法来减小搜索空间的范围:
移除不需要的搜索选项,重用 EfficientNet 中搜索的 channel sizes,接着在搜索空间中随机采样了 1000 个模型,并针对每个模型训练 10 个 epochs(使用较小的图像尺度)。搜索奖励结合了模型准确率 A,标准训练一个 step 所需时间 S 以及模型参数大小 P,奖励函数可写成: $\( A \cdot S^{w}\cdot P^{v} \)$
其中,A 是模型精度、S 是归一化训练时长,P 是参数量,w=-0.07 和 v=-005。
与 V1 的不同:
1.除了使用 MBConv 之外还使用了 Fused-MBConv 模块,加快训练速度与提升性能。
2.使用较小的 expansion ratio (之前是 6),从而减少内存的访问量。
3.趋向于选择 kernel 大小为 3 的卷积核,但是会增加多个卷积用以提升感受野。
4.移除了最后一个 stride 为 1 的 stage,从而减少部分参数和内存访问。
EfficientNetV2 缩放
作者在 EfficientNetV2-S 的基础上采用类似 EfficientNet 的复合缩放,并添加几个额外的优化,得到 EfficientNetV2-M/L。
额外的优化描述如下:
1.限制最大推理图像尺寸为 480。
2.在网络的后期添加更多的层提升模型容量且不引入过多耗时。
训练速度比较
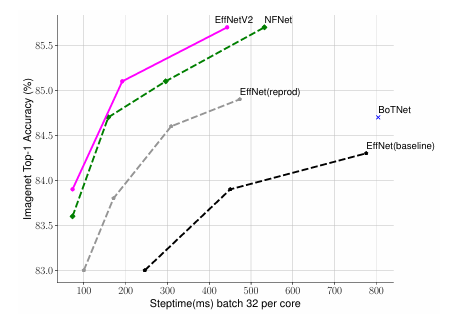
如下图所示,EfficientNetV2 模型在 ImageNet 上 top-1 acc 和 train step time,这里的训练采用固定的图像大小,不过比推理时图像大小降低 30%,而图中的 EffNet(reprod)也是采用这样的训练策略,可以看到比 baseline 训练速度和效果均有明显提升,而 EfficientNetV2 在训练速度和效果上有进一步地提升。
渐进式学习#
除了模型设计优化,论文还提出了一种 progressive learning 策略来进一步提升 EfficientNet v2 的训练速度,简单来说就训练过程渐进地增大图像大小,但在增大图像同时也采用更强的正则化策略,训练的正则化策略包括数据增强和 dropout 等。
不同的图像输入采用不同的正则化策略,这不难理解,在早期的训练阶段,我们用更小的图像和较弱的正则化来训练网络,这样网络就可以轻松、快速地学习简单的表示。然后,我们逐渐增加图像的大小,但也通过增加更强的正则化,使学习更加困难。从下表中可以看到,大的图像输入要采用更强的数据增强,而小的图像输入要采用较轻的数据增强才能训出最优模型效果。
Size=128 |
Size=192 |
Size=300 |
|
|---|---|---|---|
RandAug magnitude=5 |
78.3\(\pm\) 0.16 |
81.2\(\pm\) 0.06 |
82.5\(\pm\) 0.05 |
RandAug magnitude=10 |
78.0\(\pm\) 0.08 |
81.6\(\pm\)0.08 |
82.7\(\pm\) 0.08 |
RandAug magnitude=15 |
77.7\(\pm\) 0.15 |
81.5\(\pm\)0.05 |
83.2\(\pm\) 0.09 |
结论:
(1)即使是相同的网络,较小的图像尺寸会导致较小的网络容量,因此需要较弱的正则化。
(2)反之,较大的图像尺寸会导致更多的计算,而容量较大,因此更容易出现过拟合。
(3)当图像大小较小时,弱增强的精度最好;但对于较大的图像,更强的增强效果更好。
自适应正则化#
在早期训练阶段,使用较小的图像大小和较弱的正则化训练网络,这样网络可以轻松快速地学习简单表示。然后,逐渐增加图像大小,但也通过添加更强的正则化使学习更加困难。在逐步改进图像大小的基础上,自适应地调整正则化。假设整个训练有 N 个步骤,目标图像大小为 \(S_{e}\) ,正则化大小 \(Φ_{e}={ϕ_{e}^{}}\) ,这里 k 表示一种正则化类型,例如 dropout rate or mixup rate value。将训练分为 M 个阶段,对于每个阶段 \(1≤i≤M\) ,利用图像大小 Si 和正则化幅度对模型进行训练 \(Φ_{i}={ϕ_{i}^{k}}\) ,最后阶段 \(M\) 将图像大小 \(S_{e}\) 和正则化 \(Φ_{e}\) ,为了简单起见,启发式地选择初始图像大小 \(S_{0}\),\(Φ_{0}\) ,然后使用线性插值来确定每个阶段的值,算法 1 总结了该过程。在每个阶段开始,网络将集成前一阶段的所有权重,与 trasnformer 不同,trasnformer 的权重(例如位置嵌入)可能取决于输入长度,ConvNet 的权重与图像大小无关,可以轻松继承。本文中主要研究了以下三种正则:Dropout、RandAugment 以及 Mixup。
dropout:一种网络级的正规化,通过随机丢弃通道来减少共同适应(co-adaptation)。我们将调整 dropout 率。
RandAugment:对每幅图像分别做幅度可调的数据增强。
Mixup:图像与图像相互作用的数据增强。给定带有标签的两幅图像 \((x_{i},y_{i})\) 和 \((x_{j},y_{j})\),Mixup 根据混合比将两者混合:\(\widetilde{x_{i}}=λx_{j}+(1-λ)x_{i}\) \(\widetilde{y_{i}}=λy_{j}+(1-λ)y_{j}\),。我们将在训练期间调整混合比λ。
网络结构实现#
EfficientNet V2 在除了使用 MBConv 之外,在网络浅层使用了 Fused-MBConv 模块,加快训练速度与提升性能;使用较小的 expansion ratio(从 V1 版本的 6 减小到 4),从而减少内存的访问量; 偏向使用更小的 3×3 卷积核(V1 版本存在很多 5×5),并堆叠更多的层结构以增加感受野;移除步长为 1 的最后一个阶段(V1 版本中 stage8),因为它的参数数量过多,需要减少部分参数和内存访问。
# 反残差结构 FusedMBConv:3×3 膨胀卷积层+BN 层+Swish 激活函数+1×1 点卷积层+BN 层
class FusedMBConvBlock(nn.Module):
def __init__(self,
kernel, # 卷积核大小
input_c, # 输入通道数
out_c, # 输出通道数
expand_ratio, # 膨胀系数 1 or 4
stride, # 卷积核步长
se_ratio, # 启用 se 注意力模块
drop_rate, # 通道随机失活率
norm_layer): # 归一化层
super(FusedMBConvBlock, self).__init__()
# 膨胀通道数 = 输入通道数*膨胀系数
expanded_c = input_c * expand_ratio
# 步长必须是 1 或者 2
assert stride in [1, 2]
# 没有 se 注意力模块
assert se_ratio == 0
# 深度卷积步长为 2 则没有 shortcut 连接
self.use_res_connect = stride == 1 and input_c == out_c
self.drop_rate = drop_rate
self.has_expansion = expand_ratio != 1
layers = OrderedDict()
# Swish 激活函数
activation_layer = nn.SiLU
# 只有当 expand ratio 不等于 1 时才有膨胀卷积
if self.has_expansion:
# 3×3 膨胀卷积(膨胀系数>1) 升维
layers.update({"expand_conv": ConvBNAct(input_c,
expanded_c,
kernel_size=kernel,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# 1×1 点卷积
layers.update({"project_conv": ConvBNAct(expanded_c,
out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity)}) # 注意没有激活函数
else:
# 当没有膨胀卷积时,3×3 点卷积
layers.update({"project_conv": ConvBNAct(input_c,
out_c,
kernel_size=kernel,
norm_layer=norm_layer,
activation_layer=activation_layer)}) # 注意有激活函数
self.block = nn.Sequential(layers)
if self.use_res_connect and drop_rate > 0:
self.drop_connect = DropConnect(drop_rate)
# 只有在使用 shortcut 连接时才使用 drop_connect 层
if self.use_res_connect and drop_rate > 0:
self.drop_connect = DropConnect(drop_rate)
else:
self.drop_connect = nn.Identity()
def forward(self, x):
result = self.block(x)
result = self.drop_connect(result)
# 反残差结构随机失活
if self.use_res_connect:
result += x
return result
小结与思考#
EfficientNet V1 通过神经网络搜索技术(NAS)分析了网络深度、宽度和输入图像分辨率对模型性能的影响,并提出了一种复合模型缩放方法,通过统一的缩放系数平衡调整这三个参数,使用 SE 模块进一步提升特征表示能力。
EfficientNet V2 在 V1 的基础上引入了训练感知神经结构搜索和缩放,考虑了模型的推理和训练速度,采用渐进式学习策略和自适应正则化强度调整机制,通过联合优化准确率、参数效率和训练效率,提高了模型的训练速度和性能。
EfficientNet V2 网络结构实现中,使用了 Fused-MBConv 模块以加快训练速度和提升性能,较小的 expansion ratio 减少内存访问量,偏向使用 3×3 卷积核并通过堆叠更多层来增加感受野,移除了最后一个步长为 1 的 stage 以减少参数和内存访问。