数据并行实现#
数据并行是分布式训练中最基础和常见的并行算法。本节将重点介绍分布式数据并行(DDP)在 PyTorch 中的简单实现示例,并对数据并行的各个关键步骤如前向传播、反向传播、梯度更新等进行详细分析,以更深入地理解数据并行的实现原理和具体执行步骤。
DDP 简单实现#
这是在分布式环境下使用 2 块设备训练 resnet50 的完整例子:
我们首先需要导入了实现分布式数据并行训练所需的 Python 库。包括 PyTorch 的核心库 torch、神经网络模块 torch.nn、优化器模块 torch.optim、分布式计算模块 torch.distributed 和多进程模块 torch.multiprocessing,以及用于示例数据的视觉库 torchvision。
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
import torchvision.datasets
import torchvision.models
import torchvision.transforms as T
通过辅助函数 setup 和 cleanup,用于设置和清理分布式训练环境。函数 setup 首先指定了分布式通信的主节点地址和端口号,然后使用 dist.init_process_group 初始化进程组。而 cleanup 函数则通过 dist.destroy_process_group 来析构进程组,确保训练结束后正确释放资源。demo_basic 函数实现了分布式数据并行训练的主要逻辑。该函数首先调用之前定义的 setup 函数设置分布式环境。随后,它加载 CIFAR10 数据集,并使用 PyTorch 的 DataLoader 创建一个数据迭代器,以便在训练过程中循环读取数据批次。
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group('nccl', rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
transform = T.Compose([
T.Resize(224),
T.ToTensor(),
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
def demo_basic(rank, world_size):
print(f'Running basic DDP example on rank {rank}.')
setup(rank, world_size)
dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
sampler = DistributedSampler(dataset)
train_loader = torch.utils.data.DataLoader(dataset, batch_size=1, sampler=sampler, pin_memory=True, num_workers=4)
# create model and move it to GPU with id rank
model = torchvision.models.resnet50(weights=True).to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
for data in train_loader:
inputs, labels = data[0].to(rank), data[1].to(rank)
optimizer.zero_grad()
outputs = ddp_model(inputs)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__ == '__main__':
run_demo(demo_basic, 2)
值得注意的是,demo_basic 在当前进程的 GPU 上创建 ResNet50 模型实例,并使用 torch.nn.parallel.DistributedDataParallel 将其封装为分布式数据并行模型,同步不同进程的参数。对于每个数据批次,该函数将首先把数据移动到当前 GPU,然后前向传播计算模型输出,基于损失函数计算损失值并反向传播,最后使用优化器根据梯度更新模型参数。循环结束后,调用之前定义的 cleanup 函数析构进程组。
作为分布式的启动函数,run_demo 利用 torch.multiprocessing.spawn 启动指定数量的进程,并在每个进程中运行传入的函数。在主程序入口处,run_demo 被调用并传入了 demo_basic 函数和进程数 2,因此实现了在 2 个 GPU 上进行分布式数据并行训练。
DDP 前向传播#
接下来我们来看 Pytorch2.0 [1] 中分布式数据并行具体的实现方式,这里我们先不涉及 Pytorch2.0 或 torchdynamo 引入的编译部分,分布式系统的编译优化将在一个单独的章节中进行介绍。首先我们看看 DDP 的初始化与前向传播,以及在这个过程中是如何维护模型一致性的。
模型的一致性要求每次进行的前向传播每个进程的参数需要相同。它依赖于 torch.nn.Module 类和 DistributedDataParallel 类,在 PyTorch 中,所有的模型都会继承 Module 类(包括分布式数据并行类 DistributedDataParallel)。其中我们需要关注的是 Module 类中的两个类变量 _parameters 和 _buffers,_parameters 是指网络的参数,_buffers不是参数,但也是会被持久化保存的数据,如 BatchNorm 中的 mean 和 variance。
# torch.nn.modules.py
class Module:
...
_parameters: Dict[str, Optional[Parameter]]
_buffers: Dict[str, Optional[Tensor]]
...
DDP 在构建时,会同步各个进程的模型参数,包括_parameters 和 _buffers以达到模型的一致性。
# torch.nn.parallel.distributed.py
class DistributedDataParallel(Module, Joinable):
...
def __init__(
...
# Sync params and buffers. Ensures all DDP models start off at the same value.
_sync_module_states(
module=self.module,
process_group=self.process_group,
broadcast_bucket_size=self.broadcast_bucket_size,
src=0,
params_and_buffers_to_ignore=self.parameters_to_ignore,
)
...
同时,在每次网络传播开始前,DDP 也都会同步进程之间的 buffer,维持状态的统一。
# torch.nn.parallel.distributed.py
class DistributedDataParallel(Module, Joinable):
...
def forward(self, *inputs, **kwargs):
...
# Sync params and buffers. Ensures all DDP models start off at the same value.
_sync_module_states(
module=self.module,
process_group=self.process_group,
broadcast_bucket_size=self.broadcast_bucket_size,
src=0,
params_and_buffers_to_ignore=self.parameters_to_ignore,
)
...
DDP 计算与通信的重叠#
在分布式数据并行(DDP)中,一项重要的优化是在反向传播过程中同时进行参数更新,这一过程也被称为计算与通信的重叠。在分布式训练中,每个进程通常会在完成当前网络反向传播的同时进行梯度更新,以隐藏通信延迟。在部分梯度计算完成后,即可立即进行通信,一般通过钩子函数来实现。在通信的同时也会继续计算梯度,这样就无需等待所有计算完成后再集中进行通信,也不必在计算完成后等待通信完成,从而将通信过程覆盖到计算时间内,充分利用设备,提高了设备使用率。
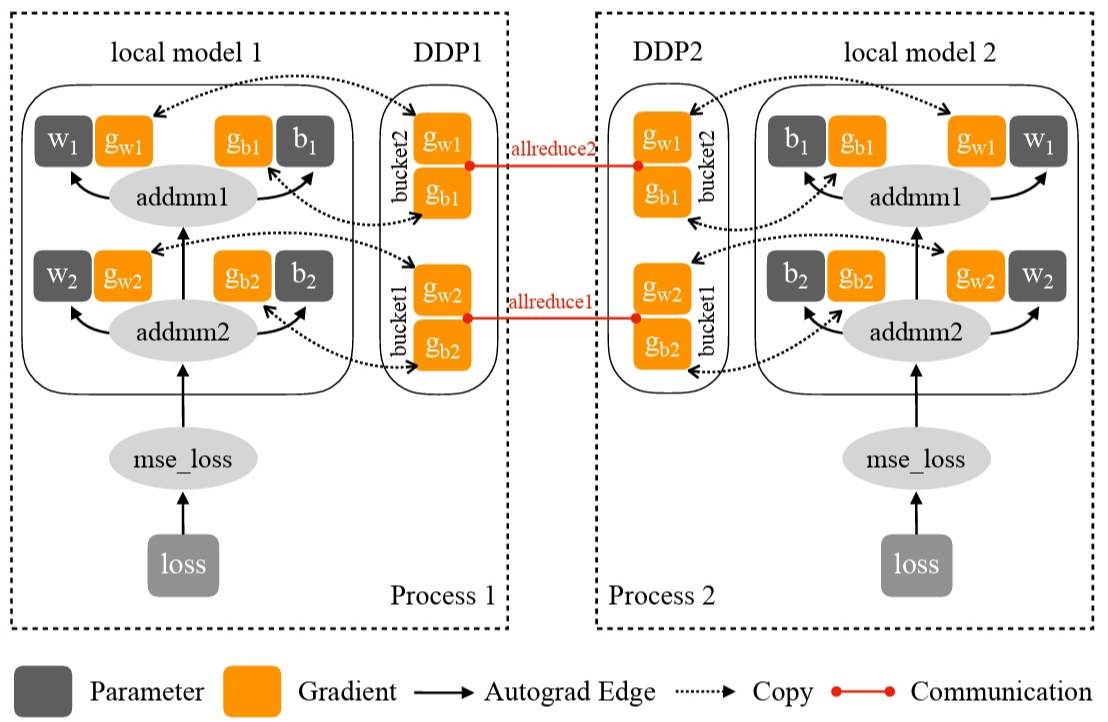
这里我们同样使用 Pytorch2.0 进行举例。在此过程中涉及到钩子函数 hook、参数桶 bucket 和归约管理器 reducer 三个关键部分。
钩子函数 hook 是在 torch.Tensor 上实现的,每次计算相对于张量的梯度时都会调用该钩子。通过钩子函数,当张量梯度计算完成后,就可以立即进行集合通信。需要注意的是,虽然 DDP 的关键代码是用 C++ 实现的,但在 C++ 和 Python 代码中,Tensor 都提供了相似的 hook 接口,实现了类似的功能。
# torch._tensor.py
class Tensor(torch._C._TensorBase):
...
def register_hook(self, hook):
r"""Registers a backward hook.
The hook will be called every time a gradient with respect to the
Tensor is computed.
...
Pytorch 使用归约管理器 reducer 在反向传播期间进行梯度同步。为提高通信效率,reducer 将参数梯度组织到多个桶 buckets 中,并对每个桶进行集合通信(可通过在 DDP 构造函数中设置 bucket_cap_mb 参数来配置桶大小)。其中参数梯度到桶的映射,在构造时基于桶大小限制和参数大小确定。模型参数按照给定模型 Model.parameters() 的大致相反顺序分配到桶中(使用相反顺序的原因是 DDP 期望在反向传播时以大致相同的顺序准备好梯度)。示例图展示了一个场景,其中 \(g_{w2}\) 和 \(g_{b2}\) 在 bucket1 中,另外两个梯度在 bucket2 中。虽然这种假设可能不总是成立,一旦发生,将损害 DDP 反向传播的速度,因为 reducer 无法在最早可能的时间启动通信。除了分桶,reducer 在构造阶段为每个参数注册了 autograd 钩子,在反向传播时当梯度准备就绪时触发这些钩子。Pytorch 使用 _ddp_init_helper 函数,进行参数的 reducer 的初始化以及参数的装桶。
# torch.nn.parallel.distributed.py
class DistributedDataParallel(Module, Joinable):
...
def __init__(
...
# Builds reducer.
self._ddp_init_helper(
parameters,
expect_sparse_gradient,
param_to_name_mapping,
static_graph,
)
...
...
def _ddp_init_helper(
self,
parameters,
expect_sparse_gradient,
param_to_name_mapping,
static_graph,
):
"""
Initialization helper function that does the following:
(1) bucketing the parameters for reductions
(2) resetting the bucketing states
(3) registering the grad hooks
(4) Logging construction-time DDP logging data
(5) passing a handle of DDP to SyncBatchNorm Layer
"""
...
如果一个参数在前向传播中没有被使用,当前参数的桶会在反向传播时永远等待缺失的梯度。如果设置了 find_unused_parameters 为 True,DDP 会分析来自本地模型的输出,从而确定在模型的子图上运行反向传播时哪些参数参与了计算。DDP 通过从模型输出遍历 autograd 图来找出未使用的参数,并将其标记为可供 reduce。在反向传播期间,reducer 只会等待未就绪的参数,但它仍会对所有桶进行 reduce 操作。将参数梯度标记为就绪不会帮助 DDP 跳过桶,但会防止其在反向传播时永远等待缺失的梯度。值得注意的是,遍历 autograd 图会带来额外开销,因此只有在必要时才应将 find_unused_parameters 设置为 True。
由于反向传播的函数 backward 直接在损失张量上调用,这超出了 DDP 的控制范围。DDP 使用在构造时注册的 autograd 钩子来触发梯度同步。当一个梯度准备就绪时,相应的 DDP 钩子会被触发,DDP 将标记该参数梯度为就绪可供 reduce。当一个桶中的所有梯度都准备就绪时,reducer 将在该桶上启动异步 allreduce 操作以计算所有进程中梯度的平均值。当所有桶都就绪时,reducer 将阻塞等待所有 allreduce 操作完成。完成后,平均梯度将被写入所有参数的 param.grad 字段。因此,在反向传播之后,不同 DDP 进程上相同的参数其 grad 字段应该是相同的。在之后的优化器步骤中,所有 DDP 进程上的模型副本可以保持同步,因为它们都从同一个状态开始,并且在每次迭代中具有相同的平均梯度。
DDP 数据加载#
我们所使用的 DataLoader 是一个迭代器,在加载 __iter__ 方法时,会根据进程数量选择对应的迭代器,分为 _SingleProcessDataLoaderIter 和 _MultiProcessingDataLoaderIter。
# torch.utils.dat.dataLoader.py
class DataLoader(Generic[T_co]):
...
def __iter__(self) -> '_BaseDataLoaderIter':
...
if self.persistent_workers and self.num_workers > 0:
if self._iterator is None:
self._iterator = self._get_iterator()
else:
self._iterator._reset(self)
return self._iterator
else:
return self._get_iterator()
...
def _get_iterator(self) -> '_BaseDataLoaderIter':
if self.num_workers == 0:
return _SingleProcessDataLoaderIter(self)
else:
self.check_worker_number_rationality()
return _MultiProcessingDataLoaderIter(self)
这些迭代器会调用使用 _reset 初始化 sampler,然后通过 _next_data 方法获取数据。
...
def __next__(self) -> Any:
with torch.autograd.profiler.record_function(self._profile_name):
if self._sampler_iter is None:
# TODO(https://github.com/pytorch/pytorch/issues/76750)
self._reset() # type: ignore[call-arg]
data = self._next_data()
...
在 _MultiProcessingDataLoaderIter 中,会加载多个进程,主进程负责维护一个索引队列(index_queue),工作进程从索引队列中获取数据索引,然后从数据集中加载数据并进行预处理。处理后的数据被放入结果队列(worker_result_queue)中,供主进程使用。
# torch.utils.data.dataLoader.py
class _MultiProcessingDataLoaderIter(_BaseDataLoaderIter):
def __init__(self, loader):
...
for i in range(self._num_workers):
# No certainty which module multiprocessing_context is
index_queue = multiprocessing_context.Queue() # type: ignore[var-annotated]
# Need to `cancel_join_thread` here!
# See sections (2) and (3b) above.
index_queue.cancel_join_thread()
w = multiprocessing_context.Process(
target=_utils.worker._worker_loop,
args=(self._dataset_kind, self._dataset, index_queue,
self._worker_result_queue, self._workers_done_event,
self._auto_collation, self._collate_fn, self._drop_last,
self._base_seed, self._worker_init_fn, i, self._num_workers,
self._persistent_workers, self._shared_seed))
w.daemon = True
w.start()
self._index_queues.append(index_queue)
self._workers.append(w)
...
其中每一个 worker 运行 _worker_loop 函数,从 index_queue 中获取 index,而后从 Dataset 中获取对应的数据。
# torch.utils.data._utils.worker.py
def _worker_loop(dataset_kind, dataset, index_queue, data_queue, done_event,
auto_collation, collate_fn, drop_last, base_seed, init_fn, worker_id,
num_workers, persistent_workers, shared_seed):
...
while watchdog.is_alive():
try:
r = index_queue.get(timeout=MP_STATUS_CHECK_INTERVAL)
except queue.Empty:
continue
...
idx, index = r
...
try:
data = fetcher.fetch(index)
except Exception as e:
if isinstance(e, StopIteration) and dataset_kind == _DatasetKind.Iterable:
data = _IterableDatasetStopIteration(worker_id)
# Set `iteration_end`
# (1) to save future `next(...)` calls, and
# (2) to avoid sending multiple `_IterableDatasetStopIteration`s.
iteration_end = True
else:
# It is important that we don't store exc_info in a variable.
# `ExceptionWrapper` does the correct thing.
# See NOTE [ Python Traceback Reference Cycle Problem ]
data = ExceptionWrapper(
where=f"in DataLoader worker process {worker_id}")
data_queue.put((idx, data))
值得注意的是,每当处理完一个 batch,就需要调用 _process_data 将一个待处理的 batch 放入 _index_queue 中等待某个进程来处理。这可以使得,在使用当前批次的数据进行训练时,同时加载下一个批次的数据,而不需要在下一次迭代开始使再进行数据的加载,将数据加载的等待时间大大缩减。
# torch.utils.data.dataLoader.py
class _MultiProcessingDataLoaderIter(_BaseDataLoaderIter):
def _next_data(self):
while True:
...
# Check if the next sample has already been generated
if len(self._task_info[self._rcvd_idx]) == 2:
data = self._task_info.pop(self._rcvd_idx)[1]
return self._process_data(data)
def _process_data(self, data):
self._rcvd_idx += 1
self._try_put_index()
if isinstance(data, ExceptionWrapper):
data.reraise()
return data
如果设置了 pin_memory=True,则主进程会启动一个内存固定线程,该线程从结果队列中获取数据,并使用 _pin_memory_loop 将其复制到设备内存中。复制后的数据被放入数据队列中,供主进程使用。
# torch.utils.data.dataLoader.py
class _MultiProcessingDataLoaderIter(_BaseDataLoaderIter):
def __init__(self, loader):
...
pin_memory_thread = threading.Thread(
target=_utils.pin_memory._pin_memory_loop,
args=(self._worker_result_queue, self._data_queue,
current_device,
self._pin_memory_thread_done_event, self._pin_memory_device))
在分布式环境下,通过 DistributedSampler 可以获取到基于设备索引的数据切分。
# torch.utils.data.distributed.py
class DistributedSampler(Sampler[T_co]):
def __iter__(self) -> Iterator[T_co]:
if self.shuffle:
# deterministically shuffle based on epoch and seed
g = torch.Generator()
g.manual_seed(self.seed + self.epoch)
indices = torch.randperm(len(self.dataset), generator=g).tolist() # type: ignore[arg-type]
else:
indices = list(range(len(self.dataset))) # type: ignore[arg-type]
if not self.drop_last:
# add extra samples to make it evenly divisible
padding_size = self.total_size - len(indices)
if padding_size <= len(indices):
indices += indices[:padding_size]
else:
indices += (indices * math.ceil(padding_size / len(indices)))[:padding_size]
else:
# remove tail of data to make it evenly divisible.
indices = indices[:self.total_size]
assert len(indices) == self.total_size
# subsample
indices = indices[self.rank:self.total_size:self.num_replicas]
assert len(indices) == self.num_samples
return iter(indices)
DDP 性能分析#
我们使用 torch.profiler.profile 对 DDP 的过程进行性能分析。只需要对训练的循环进行简单嵌套,就能得到清晰的具体分析结果。
Configuration |
GPU Summary |
|---|---|
Number of Worker(s): 2 |
Name: Tesla V100-SXM2-16GB |
Device Type: GPU |
Compute Capability: 7.0 |
设备使用了两张 V100-SXM2-16GB 并使用 NV-Link 连接。

从 torch.profiler.profile 对 ResNet50 的性能分析结果可以看到,计算与通信的重叠几乎覆盖了整个反向传播的过程(反向传播的计算时间约为前向传播的两倍,图中重叠的部分约为只计算部分的两倍,只通信的部分可以忽略不记)

同样,在追踪视图中可以看到,反向传播的主要函数 autograd::engine::evaluate_function:ConvolutionBackward0 与集合通信的函数 nccl:all_reduce 执行是重叠的。
DDP 反向传播中计算与通信的重叠导致无需等待所有计算完成后再集中进行通信,也不必在计算完成后等待通信完成,提高了设备使用率。